从零开始的神经网络
August_Light
·
·
科技·工程
“正如每个细胞都有其独特的生命,即使是机械和电子数据,当它们达到某种复杂程度时,也可能产生一种叫做‘灵魂’的东西。”
Prerequisites
- 基础多元微积分(导数、梯度)
- 基础线性代数(矩阵运算)
Supervised Learning
这里是一些生活中常见的问题:
- 图片 \xrightarrow{\text{OCR}} 文字
- 中文 \xrightarrow{\text{翻译}} 英语
- 商品参数 \xrightarrow{\text{价格预测}} 商品价格
它们的共同点是都可以被写为一个映射:
x \xrightarrow{f} y
我们的目标,就是寻找 f 这个规律。
但是我们不可能对于总体中的每一个 x 都求出对应的 y。我们能做的,只有收集样本数据 (x_1, y_1), (x_2, y_2), \cdots,然后尝试学习样本中的规律。这种根据已有数据进行学习的方式被称为 Supervised Learning(监督学习)。
即我们需要找到一个函数 f,使得
f(x_i) \approx y_i
但是函数空间那么大,寻找任意函数 f 是不可能的。因此我们需要根据我们的先验知识,事先为函数设计一个结构 f = h_\theta,其中 \theta 为可调节参数。
举个例子,对于输入为实数 x,我们可以把 h 设计为一次函数:
h_\theta(x) = \theta_0 + \theta_1 x
后续问题的焦点分为两叉:
- 模型设计:人为设计一个合适的 h。
- 最优化:对于固定的 h,最优化参数 \theta。
常见监督学习问题
Regression
如果输出值是一个实数或实数向量,则这种监督学习问题被称为 Regression(回归)。即对于输入 x_i 和输出实数向量 y_i,求函数 h_\theta 使得
h_\theta(x_i) \approx y_i
后文中我们主要讨论回归问题。
Classification
如果输出值是一个有限的离散值,则这种监督学习问题被称为 Classification(分类)。
常见分类问题有两种:
- 硬分类:模型直接输出类别。
- 软分类:模型输出每个类别的概率分布。
- 对于软分类取一个 \argmax 可以得到硬分类。
有时可以将分类问题转化为回归问题。比如,当回归的输出大于阈值时分在第一类,小于阈值时分在第二类,这样可以完成一个二分类。
Loss function & Optimizer
怎么衡量 h_\theta(x_i) \approx y_i?我们可以定义一个函数 \operatorname{cost} 来衡量它们之间的差距:
\operatorname{cost}(h_\theta(x_i), y)
一个经常使用的定义为 \operatorname{cost}(h_\theta(x_i), y) = \lVert h_\theta(x_i) - y_i \rVert^2,不直接使用 \lVert h_\theta(x_i) - y_i \rVert 是因为它在零点处不可导。
我们想知道参数 \theta 好不好,只需要将所有样本上的 \operatorname{cost} 加起来就行了,称为 loss function(损失函数):
L(\theta) = \sum_i \operatorname{cost}(h_\theta(x_i), y_i)
我们的目标就是找到一个 \theta 使得 L 最小:
\argmin_\theta L(\theta)
Optimizer 就是专门干这个活的。实际写代码时,我们可以直接调用各种不同 optimizer 的 API。但是为了对其工作原理有一定把握,我们看一个具体的案例。
Gradient Descent
假设我们目前的参数是 \theta,接下来怎么更新 \theta 能够尽量让 L 变小?根据多元微积分知识,我们应该往这个方向上走:
- \nabla_\theta L
我们加入一个量纲转换的常数 \alpha,就得到了更新 \theta 的公式:
\theta \gets \theta - \alpha \nabla_\theta L
此处的 \alpha 被称为 learning rate(学习率),因为它衡量了学习时一步走多大。
通过这一公式不断地更新 \theta,应当可以想象到 L 会收敛在一个局部极小值。这种最优化方法称为 Gradient Descent(梯度下降法)。注意我们永远无法保证我们会抵达全局最小值,在更优的 optimizer 中我们会加入其它启发式的方法来缓解这一问题。
此处的参数 \alpha 与模型参数 \theta 是不一样的——\theta 是学习出来的,而 \alpha 是人为设定的影响学习过程的量。这种特别的参数被称为 hyperparameter(超参数),我们平时说的“调参”调整的就是这类参数。
关于梯度
除了梯度下降法,许多其它优化算法也需要用到 \nabla_\theta L。毕竟如果不使用一阶导信息我们就只能求出 L(\theta) 的值,简单情况下使用模拟退火等算法说不定还能救一救,但是维度一高就完了。
因此,当我们在设计函数 h 的时候,还需要寻找快速求解 h 的梯度的方法。
事实上,在构造 h 的时候,我们可以记录所有中间变量之间的关系构成 computational graph(计算图),通过全导数公式自动计算导数。这被称为 automatic differentiation(自动求导)。
基础的神经网络
现在我们已经大致理解了最优化的内容,该看看怎么设计 h 了。
线性变换
最简单地,我们将 h 设计为一个仿射变换(一次函数):
y = h_{W,b}(x) = W x + b
这个常数项看起来有点丑。加一位常数即可规避常数项:
\begin{bmatrix} x \\ 1 \end{bmatrix}
将这个 1 吸收进 x,将 b 吸收进 W,即可简化原式:
y = h_W(x) = W x
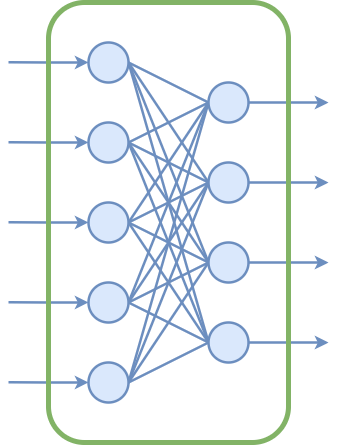
### 线性变换的复合
叠多层线性变换会不会使得模型自由度更高?很遗憾,并不会。因为线性变换的复合依然是线性变换:
$$W_2 (W_1 x) = (W_2 W_1) x$$
多层线性变换等价于一层线性变换。
### 线性变换的局限性
线性变换可以解决一切问题吗?很遗憾×2,并不能。
对于两个布尔值 $(x_1, x_2) \in \{(0, 0), (0, 1), (1, 0), (1, 1)\}$,定义它们的逻辑异或为:
$$x_1 \operatorname{XOR} x_2 = \begin{cases}
1, \quad x_1 \ne x_2 \\
0, \quad x_1 = x_2 \\
\end{cases}$$
这是一个硬分类问题,我们希望让线性模型学习这个函数。
$$h_\theta(x) = \theta_0 + \theta_1 x_1 + \theta_2 x_2 \longrightarrow \text{output} = \begin{cases}
1, \quad h_\theta(x) \ge 0 \\
0, \quad h_\theta(x) < 0 \\
\end{cases}$$
但是不难发现,没有任何一组参数 $\theta$ 可以完美地学习它,因为不可能在平面上找到一条直线将输出为 $0$ 和输出为 $1$ 的点分开:
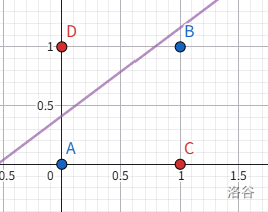
如此简单的问题都解决不了,线性变换的模型真是有点弱了。
## 多项式变换及其局限性
如果我进一步将线性变换改为多项式的变换呢?很遗憾,也不够强。一个固定次数的多项式,终究是无法逼近更高次数的多项式的。
因此,接下来我们的模型中不可避免地需要引入**非多项式的函数**。
## Activation function
我们往模型的两层全连接层中引入非多项式的连续函数 $\sigma$,称为 **activation function(激活函数)**,网络中的这一层称为 **activation layer(激活函数层)**:
$$\boxed{
h(x) = W_2 \sigma(W_1 x)
}$$
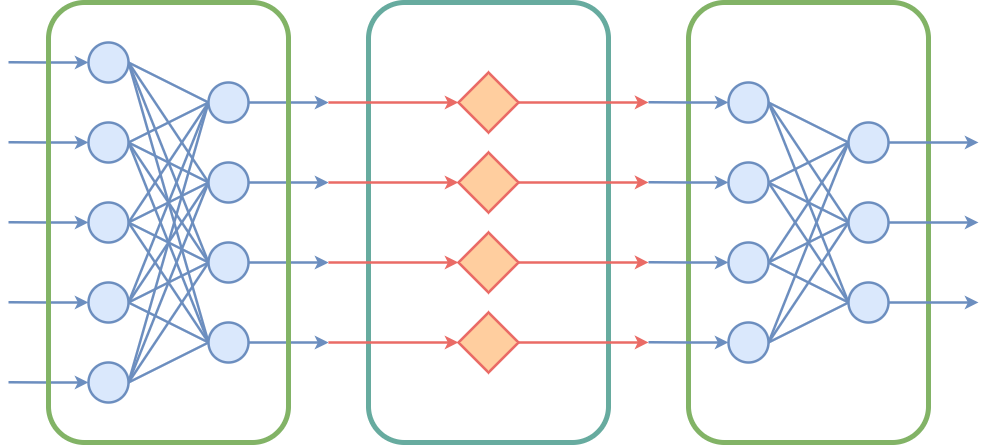
中间的这一层称为 hidden layer(隐藏层),它的宽度与输入输出的宽度无关,可以任意人为设定(如示意图中输入宽度为 $5$ 而输出宽度为 $3$,我们将隐藏层宽度指定为 $4$)。
反复叠加全连接层和激活函数层,我们就得到了 **multilayer perceptron(多层感知机)**,简称 **MLP**。
### 常用激活函数
Rectified Linear Unit,俗称 **ReLU**:
$$\boxed{
\operatorname{ReLU}(x) = \max(0, x)
}$$
Sigmoid:
$$\boxed{
\operatorname{sigmoid}(x) = \frac 1 {1 + e^{-x}}
}$$
Sigmoid 函数是一个单调递增的 S 形函数。注意它把实数轴映射到了 $(0,1)$ 区间,有时可以当作概率使用:
$$(-\infty, \infty) \xrightarrow{\operatorname{sigmoid}} (0, 1)$$
激活函数也不是一定要写死的,可以有可学习参数。例如 ReLU 的变种 PReLU:
$$\operatorname{PReLU}_a(x) = \max(0, x) + a \min(0, x)$$
## Backpropagation
对于 MLP 中的每一个特定权重 $w$,optimizer 在工作时需要求出
$$\frac {\partial L} {\partial w}$$
在这一过程中,我们显然需要从后往前逐层求出偏导数。因此计算梯度的整个过程被称为 **backpropagation(反向传播)**。相对应地,根据输入逐层计算到输出层的这一过程被称为 **forward propagation(前向传播)**。
反向传播是无需手动实现的,因为自动求导器早在神经网络搭建时就已经构造好了计算图。
# 万能近似定理
[Universal approximation theorem - Wiki](https://en.wikipedia.org/wiki/Universal_approximation_theorem)
该定理深刻地揭示了非多项式的激活函数带来的优良性质。
不省略隐藏的截距 $b$,令 $h(x) = W_2 \cdot (\sigma \circ (W_1 \cdot x + b))$。
**万能近似定理**:对于非多项式的 $\mathbb R \mapsto \mathbb R$ 的连续函数 $\sigma$,对于从任意 $\mathbb R^n$ 的一个紧子集 $K$ 到 $\mathbb R^m$ 的连续函数,对于任意 $\varepsilon > 0$,存在隐藏层宽度 $k$ 与对应参数 $W_1, W_2, b$ 使得
$$\sup_{x \in K} \lVert h(x) - f(x) \rVert < \varepsilon$$
即 $h$ **一致收敛**到 $f$。$\sup$ 代表上确界,可以理解为 $\max$ 的推广。紧子集可以理解为闭区间的推广,在紧集上函数必有界。
这个定理虽然保证了我们的神经网络可以一致逼近其它连续函数,但是并未具体给出参数的设定方法,最优化总是一个难题。