数论函数与筛法 (Part 1)
Alex_Wei
·
2026-03-06 09:25:30
·
算法·理论
Part 2 还在施工 & 会补充一些困难的莫反题目。欢迎捉虫或提供好题。
洛谷 & cnblogs
本篇笔记介绍了数论函数和筛法相关的知识点。部分定义和记号见 同余理论。
定义与记号
数论函数:定义域为正整数的函数称为 数论函数 ,可以看成数列。常见数论函数的值域为整数。
加性函数:若对任意 a, b\in \mathbb{N} ^ + 且 a\perp b ,均有 f(ab) = f(a) + f(b) ,则称 f 为 加性函数 。注意区分数论的加性函数和代数的加性函数 f(a + b) = f(a) + f(b) 。
积性函数:若对任意 a, b\in \mathbb{N} ^ + 且 a\perp b ,均有 f(ab) = f(a)f(b) ,则称 f 为 积性函数 。f(1) = 1 是必要条件。
完全积性函数:若对任意 a, b\in \mathbb{N} ^ {+} ,均有 f(ab) = f(a)f(b) ,则称 f 为 完全积性函数 。完全积性函数是积性函数。
数论函数的 加法 :对数论函数 f, g ,f + g 表示 f 和 g 的对应位置相加,即 (f + g)(x) = f(x) + g(x) 。
数论函数的 数乘 :对数 c 和数论函数 f ,c\cdot f 表示 f 的各个位置乘 c ,即 (c\cdot f)(x) = c \cdot f(x) 。一般记为 cf 。积性函数的数乘不是积性函数 (考虑 f(1) = 1 的必要条件)。
数论函数的 点乘 :对数论函数 f, g ,f \cdot g 表示 f 和 g 的对应位置相乘,即 (f \cdot g)(x) = f(x)g(x) 。一般记为 fg 。两个积性函数的点乘是积性函数 。
积性函数是这篇博客的主角。为什么它如此重要呢?因为积性函数由它在质数幂处的取值完全确定。给定 n ,计算 n 在唯一分解下每个质数幂处 f 的取值,就能得到 f(n) 。
关于常见积性函数,见 2.2 小节。
积性函数的性质在数论函数和质因数分解之间建立了桥梁,于是很多积性函数的筛法都和质因数分解当中最基本的元素——质数息息相关。因此,我们首先需要学习质数筛法。
1. 质数筛法
质数筛法是数论函数体系当中最基本的知识点,也是大部分数论题目所必需的算法。
质数判定的基本想法是寻找合数满足的性质,并证明质数不满足这些性质。从合数满足的性质出发,得到判定合数的必要条件(取否定,即判定质数的充分条件),再考虑证明其充分性。
关于更快速的质数判定,见质因数分解笔记的 Miller-Rabin。
1.1 基本算法
1.1.1 试除法
判定 n 是不是质数。
如果 n 是合数,那么存在因数 d\in [2, n - 1] 。如果 d \geq \sqrt n ,那么 n / d 也是非平凡因数且 n / d \leq \sqrt n 。
因此,如果 n 是合数,那么存在因数 d\in [2, \sqrt n] 。反过来,如果存在这样的 d ,那么 n 显然是合数。
时间 \mathcal{O}(\sqrt n) 。
1.1.2 倍数筛
判定 2 到 n 的每个数是不是质数。
如果直接对每个数使用试除法,则时间复杂度 \mathcal{O}(n\sqrt n) 。
我们希望找到因数-倍数关系判定质数。试除法的问题在于,对于每个倍数,难以快速求出其所有因数,导致枚举了太多不是因数的数。但对于一个因数,我们很容易找到其所有倍数。这引出了接下来的倍数筛。
如果 x 是合数,那么存在非平凡因数 d 。相反,如果 x 是质数,那么不存在这样的 d 。
如果 d\in [2, x - 1] 是 x 的因数,那么存在 k > 1 使得 x = kd 。于是,我们用一个数的不是它自己的倍数标记出合数。
枚举 2\sim n 的所有数 x ,并将 2x, 3x, \cdots 标记为合数,直到 kx > n 。过程结束后没有被标记的数就是质数。
时间 \mathcal{O}(\sum_{i = 1} ^ n n / i) = \mathcal{O}(n\ln n) 。
1.1.3 区间筛
判断 l 到 r 的每个数是不是质数。
在倍数筛的过程中,如果 x 有非平凡因数 d ,那么 d 和 x / d 一定有一个不超过 \sqrt x 。因此,仅使用 [2, \sqrt x] 筛去所有合数即可。
推广到本题,就是仅使用 [2, \sqrt r] 的每个数标记 l, r 之间的合数。
时间 \mathcal{O}((r - l)\ln r + \sqrt r) 。
1.2 埃氏筛
判定 2 到 n 的每个数是不是质数。
由算术基本定理,如果 x 是合数,那么存在 质因数 d\in [2, x - 1] 。相反,如果 x 是质数,那么不存在这样的 d 。基于此,埃氏筛用 已经筛出的质数 的倍数标记合数。
算法流程:从 2 到 n 枚举所有数 x 。若 x 没有被标记,则 x 是质数,并将 x 的除了本身的倍数标记为合数。
小优化:因为合数的最小质因数不超过其平方根,所以我们可以从 x ^ 2 开始标记,不影响复杂度。这个思想很重要,因为外层只需枚举到 \sqrt n 。埃氏筛提供了亚线性计算特殊积性函数的框架:考虑如何在每一轮中加入新标记的合数的贡献。
代码如下:
for(int i = 2; i < N; i++) {
if(!vis[i]) {
pr[++cnt] = i;
for(int j = i + i; j < N; j += i) vis[j] = 1;
}
}复杂度证明
结论(质数倒数和的数量级)
不超过 n 的质数的倒数之和是 \mathcal{O}(\log\log n) 。
证明
每个数只会被其质因数标记到,所以
\sum_{p\in \mathbb{P},\ p\leq n} \frac n p = \sum_{p\in \mathbb{P},\ p\leq n} \left(\left\lfloor\frac n p\right\rfloor + \mathcal{O}(1)\right) = \sum_{i = 1} ^ n \omega(i) + \mathcal{O}(n),
即
\sum_{p\in \mathbb{P},\ p\leq n} \frac 1 p = \frac 1 n \sum_{i = 1} ^ n \omega(i) + \mathcal{O}(1).
根据 d(i) 的计算式,
\sum_{i = 1} ^ n 2 ^ {\omega(i)} \leq \sum_{i = 1} ^ n d(i) = \mathcal{O}(n\log n).
根据 2 ^ x 的凸性和 Jensen 不等式(琴生不等式),得
2 ^ {\frac{\sum_{i = 1} ^ n \omega(i)} n} \leq\frac 1 n\sum_{i = 1} ^ n 2 ^ {\omega(i)} = \mathcal{O}(\log n).
取对数,
\sum_{p\in \mathbb{P},\ p\leq n} \frac 1 p = \frac 1 n \sum_{i = 1} ^ n \omega(i) + \mathcal{O}(1) = \mathcal{O}(\log \log n).
\square
因此,埃氏筛的时间为 \mathcal{O}(n\log\log n) 。
1.3 线性筛
线性筛也称欧拉 Euler 筛。
埃氏筛用质数的倍数筛去合数,导致一个合数会被它的多个质因数筛到。如果让每个合数只被筛一次,就可以做到线性了。
考虑用每个合数的 最小质因数 筛去它。设当前筛到 i ,有两种思路:
一是当 i 是质数时,筛去最小质因数是 i 的合数,即求出所有 j 使得 ij 的最小质因数为 i 。这要求 j 的最小质因数不小于 i ,也就是当前还没有被标记的所有数。可以用链表维护,但是较麻烦。
二是对每个 i ,筛去除掉最小质因数 j 之后的值等于 i 的合数。这要求 j 不大于 i 的最小质因数,因此 j 只能是所有不大于 i 的最小质因数的质数。从小到大枚举质数 j ,直到 j 等于 i 的最小质因数时退出,判定条件是 j\mid i 。
显然采用第二种思路。
另一种理解方式是,对于每个 i ,设其最小质因数为 p ,则对于不大于 p 的质数 q ,iq 的最小质因数为 q 。将所有 iq 标记为合数,则每个合数 c 仅在 i = c / q 时以 iq 的形式被删去,其中 q 是 c 的最小质因数。
综上,得到如下算法。从 2 到 n 枚举 i :
时间 \mathcal{O}(n) 。模板题 代码。
#include <bits/stdc++.h>
using namespace std;
constexpr int N = 1e8 + 5;
bool vis[N];
int n, q, pr[N / 16], cnt;
int main() {
cin >> n;
for(int i = 2; i <= n; i++) {
if(!vis[i]) pr[++cnt] = i;
for(int j = 1; j <= cnt && i * pr[j] <= n; j++) {
vis[i * pr[j]] = 1;
if(i % pr[j] == 0) break;
}
}
cin >> q;
while(q--) {
int x;
scanf("%d", &x);
printf("%d\n", pr[x]);
}
return 0;
}1.4 线性筛积性函数
线性筛提供了在线性时间内筛出具有特殊性质的 积性函数 在 1\sim n 处所有取值的基本框架。
只要可以在 \mathcal{O}(1) 时间内计算积性函数 f 在任意质数幂处的取值 f(p ^ k) ,就可以线性筛出 f 在 1\sim n 处的所有取值。
注意 :这只是 f 可线性筛的充分条件。存在更弱的条件使得 f 可线性筛,见 2.2 小节。
根据积性函数的性质,考虑求出 l_i 表示 i 的最小质因数 p 的最高次幂 p ^ {\nu_p(i)} 。若 i 是质数幂,则直接计算,否则 l_i\neq i ,f(i) = f(l_i) f(i / l_i) 。
for(int i = 2; i < N; i++) {
if(!vis[i]) pr[++cnt] = i, f[i] = ..., low[i] = i; // 单独算 f(p)
for(int j = 1; j <= cnt && i * pr[j] < N; j++) {
vis[i * pr[j]] = 1;
if(i % pr[j] == 0) { // i 与 p 不互质
low[i * pr[j]] = low[i] * pr[j];
if(i == low[i]) f[i * pr[j]] = ...; // i = p ^ k,单独算 f(p ^ {k + 1})
else f[i * pr[j]] = f[i / low[i]] * f[low[i * pr[j]]];
break;
}
low[i * pr[j]] = pr[j];
f[i * pr[j]] = f[i] * f[pr[j]]; // i 与 p 互质,f(ip) = f(i) * f(p)
}
}2. 狄利克雷卷积
狄利克雷 Dirichlet 卷积是数论函数的基本运算。
2.1 定义
我们知道加法卷积
c_k = \sum_{i + j = k} a_ib_j.
但加法卷积不保留积性。将加法换成乘法,结果如何?
h(n) = \sum_{dd' = n} f(d) g(d')
称为 狄利克雷卷积 ,记为 h = f * g 。按照定义式计算狄利克雷卷积,时间为调和级数的 \mathcal{O}(n\log n) 。
狄利克雷卷积的另一种更常见的形式为
h(n) = \sum_{d\mid n} f(d) g\left(\frac n d\right).
2.2 常见数论函数
设 n 的唯一分解为 \prod_{i = 1} ^ m p_i ^ {c_i} ,以下列出了一些常见的积性函数。除了 \omega 是加性函数以外,其余所有函数都是积性函数。
单位函数
\epsilon(n) = [n = 1].
当 n = 1 时取值为 1 ,否则为 0 。
单位函数 \epsilon 是狄利克雷卷积的单位元。
常数函数
1(n) = 1.
所有位置的取值均为 1 。
一个函数和常数函数的狄利克雷卷积称为狄利克雷前缀和,其结果函数在 n 处的取值为原函数在 n 的所有因数处的取值和。
恒等函数
\mathrm{id}(n) = n.
所有位置的取值均为本身。更一般地,
\mathrm{id}_k(n) = n ^ k.
除数函数
\sigma_k(n) = \sum_{d\mid n}d ^ k.
$\sigma_k(n)$ 有计算式
$$
\begin{cases}
\prod_{i = 1} ^ m (c_i + 1), & k = 0; \\
\prod_{i = 1} ^ m \frac{p_i ^ {(c_i + 1)k} - 1}{p_i - 1}, & k > 0.
\end{cases}
$$
根据乘法分配律,$\sigma_k(n)$ 也就是 $n$ 的所有因数的 $k$ 次方之和可写作
$$
\prod_{i = 1} ^ m(1 + p_i ^ k + p_i ^ {2k} + \cdots + p_i ^ {c_ik}).
$$
等比数列求和即可。
**欧拉函数**
$$
\varphi(n) = \sum_{i = 0} ^ {n - 1} [i\perp n].
$$
$0\sim n - 1$ 中与 $n$ 互质的数的个数。
关于欧拉函数,见第四章。
**本质不同质因数函数**
$$
\omega(n) = \sum_{p \in \mathbb{P}} [p\mid n].
$$
$n$ 的本质不同质因数个数。
**莫比乌斯函数**
$$
\mu(n) =
\begin{cases}
1, & n = 1; \\
0, & \exists d > 1, d ^ 2\mid n; \\
(-1) ^ {\omega(n)}, & \mathrm{otherwise}.
\end{cases}
$$
若 $n$ 有大于 $1$ 的平方因数,那么 $\mu(n) = 0$,否则 $\mu(n) = (-1) ^ {\omega(n)}$。
莫比乌斯函数是常函数的狄利克雷卷积逆元,在数论函数与筛法中有着重要地位。关于莫比乌斯函数和莫比乌斯反演,见第五章。
### 2.3 性质
最基本的交换律,结合律与分配律。
> **性质 1.1(交换律)**
>
> 狄利克雷卷积有 **交换律**。
>
> **证明**
> $$
> \begin{aligned}
> (f * g)(n) & = \sum_{dd' = n} f(d) g(d').
> \end{aligned}
> $$
> $d, d'$ 的地位相同。交换 $d$ 和 $d'$,可知 $f * g = g * f$。$\square
性质 1.2(结合律)
狄利克雷卷积有 结合律 。
证明
\begin{aligned}
((f * g) * h)(n) & = \sum_{dd'd'' = n} f(d) g(d') h(d'').
\end{aligned}
d, d', d''$ 的地位相同。先结合 $d'$ 和 $d''$,可知 $(f * g) * h = f * (g * h)$。$\square
性质 1.3(分配律)
狄利克雷卷积有 分配律 。
证明
\begin{aligned}
((f + g) * h)(n) & = \sum_{dd' = n} (f(d) + g(d)) h(d') \\
& = \sum_{dd' = n} f(d)h(d') + \sum_{dd' = n} g(d)h(d') \\
& = (f * h + g * h)(n).
\end{aligned}
因此 (f + g) * h = f * h + g * h 。\square
注意 :点积和狄利克雷卷积之间不具有交换律。(f\cdot g) * h \neq (f * h) \cdot g 。
考察卷积的单位元。容易发现:
性质 2(单位元)
**证明**
考虑 $(\epsilon * f)(n)$ 的计算式,只有 $f(n)$ 这一项非零。所以 $(\epsilon * f)(n) = f(n)$。$\square
单位函数 \epsilon 是狄利克雷卷积的 单位元 。这也是其名称的由来。
在单位元的基础上,定义狄利克雷卷积的逆元 f ^ {-1} ,满足 f * f ^ {-1} = f ^ {-1} * f = \epsilon 。
性质 3(逆元)
**证明**
设 $g = f ^ {-1}$。
- 当 $f(1) = 0$ 时,$f(1)g(1) = 0\neq \epsilon(1)$。所以无论如何 $g$ 都不存在。
- 当 $f(1) \neq 0$ 时,$g(1) = \frac 1 {f(1)}$。
对于 $n > 1$,通过 $\sum_{d\mid n} g(d)f(n / d) = 0$ 得到递推式
$$
g(n) = -\frac{\sum_{d \mid n \land d \neq n} g(d)f(n / d)} {f(1)}.
$$
这同时说明了 **逆元唯一**。$\square
计算逆元的时间也是 \mathcal{O}(n\log n) 。
性质 3 说明只要 g(1) \neq 0 ,就可以计算除法 f * g ^ {-1} 。
性质 4(消去律)
**证明**
**充分性**:$f * h = g * h\implies f * h * h ^ {-1} = g * h * h ^ {-1} \implies f = g$。
**必要性**:$f = g\implies f * \epsilon = g * \epsilon$。$\square
等式两侧同时卷相同的可逆数论函数,等式仍然成立。
性质 5(乘法保留积性)
积性函数的狄利克雷卷积是积性函数 。
证明
考虑积性函数 f 和 g 的狄利克雷卷积 h 。
若 n\perp m ,则对于任意 d_1\mid n 和 d_2\mid m ,d_1\perp d_2 。因此,
\begin{aligned}
h(n)h(m) & = \left(\sum_{d_1d_1' = n} f(d_1) g(d_1' )\right)\left(\sum_{d_2d_2' = m} f(d_2) g(d_2')\right) \\
& = \sum_{dd' = nm} f(d) g(d') & (d = d_1d_2) \\
& = h(nm).
\end{aligned}
第二步用到了两个条件:
\square
性质 5 很重要。它说明 狄利克雷卷积保留积性 。
性质 6(除法保留积性)
积性函数的狄利克雷卷积逆元是积性函数。
证明
证明来自 OI-Wiki。
设 g = f ^ {-1} 。回忆积性函数 f 一定满足 f(1) = 1 。
根据 f 的积性可知 g(1) = \frac 1 {f(1)} = 1 ,所以 g(n) = g(1) g(n) 。
考虑数学归纳法。对 nm 的大小归纳。
对于 n, m > 1 且 n\perp m ,假设对任意 xy < nm 且 x\perp y ,均有 g(xy) = g(x)g(y) 。
当 n = 1 或 m = 1 时,命题显然成立。因此,只需证明 g(nm) = g(n)g(m) 。
\begin{aligned}
g(nm) & = -\sum_{d d' = nm\land d\neq nm} g(d)f(d') \\
& = -\sum_{d_1d_1' = n\land d_2d_2' = m\land d_1d_2 \neq nm} g(d_1) g(d_2) f(d_1')f(d_2') \\
& = f(1) ^ 2 g(n) g(m) -\sum_{d_1d_1' = n \land d_2d_2' = m} g(d_1) g(d_2) f(d_1') f(d_2') \\
& = g(n)g(m) - \left(\sum_{d_1d_1' = n} g(d_1) f(d_1')\right) \left( \sum_{d_2d_2' = m} g(d_2) f(d_2')\right) \\
& = g(n)g(m) - \epsilon(n) - \epsilon(m) \\
& = g(n)g(m).
\end{aligned}
最后一步的依据是 n, m > 1 。\square
性质 5 和性质 6 告诉我们:积性函数的狄利克雷卷积与狄利克雷卷积逆是积性函数 。
注意 :积性函数的和与差不是积性函数。
2.4 线性筛狄利克雷卷积
根据积性函数的狄利克雷卷积是积性函数的结论,考虑使用线性筛筛出 h = f * g ,其中 f, g 是积性函数。
写出 h 的表达式:
h(n) =
\begin{cases}
1, & n = 1; \\
\sum_{c = 0} ^ k f(p ^ c)g(p ^ {k - c}), & n = p ^ k; \\
h(p ^ k)h(m), & n = p ^ k m \ (m > 1\land p\nmid m).
\end{cases}
其中 p 是质数,k 是正整数。
对于第一种情况和第三种情况,使用 1.4 线性筛积性函数的技巧直接计算。
关键在于第二种情况。若已知 f, g 在质数幂处的取值,则需要 \mathcal{O}(k) 的时间。
当 f 是完全积性函数时,h(p ^ k) = f(p)h(p ^ {k - 1}) + g(p ^ k) ,可以 \mathcal{O}(1) 计算。对于 g 同理。
尝试估计第二种情况的复杂度 T(n) 。证明来自 EI。
所有不大于 \sqrt[k] n 的质数产生 \mathcal{O}(k) 的贡献,因此
T(n) = \sum_{x = 1} ^ {\log n} x\pi(\lfloor\sqrt[x]n\rfloor) \approx \sum_{x = 1} ^ {\log n} \frac {x\sqrt[x] n}{\ln \sqrt[x] n} = \frac 1 {\ln n} \sum\limits_{x = 1} ^ {\log n} x ^ 2\sqrt[x] n.
当 x = 1 时,x ^ 2\sqrt[x] {n} = n 。
当 2\leq x\leq \log n 时,因为 x ^ 2 递增,\sqrt [x] {n} 递减,所以
x ^ 2\sqrt[x]{n} \leq (\log_2 ^ 2 n) \cdot\sqrt n = \mathcal{O}(n).
因此
T(n) = \frac 1 {\ln n} \sum_{i = 1} ^ {\log_2 n} \mathcal{O}(n) = \mathcal{O}(n).
使用线性筛求出两个 在质数幂处取值已知 的积性函数的狄利克雷卷积在 1\sim n 处的取值的时间复杂度为 \mathcal{O}(n) 。这给出了积性函数可线性筛的更弱条件:在 \mathcal{O}(k) 的时间内计算质数幂处的取值。
2.5 狄利克雷前缀和
前置知识 :高维前缀和。
任意数论函数 f 与常数函数 1 卷积得到 g 。称 g = f * 1 为 f 的 狄利克雷前缀和 ,则
g(n) = \sum_{d\mid n} f(d).
狄利克雷前缀和用途广泛,因为对每个 n 计算给定数论函数在其所有因数处的取值之和有良好的实际含义。其逆运算为狄利克雷差分,相当于 f * \mu ,将在第四章介绍。
将正整数 n 写成无穷序列 a_n = \{c_1, c_2, \cdots, c_i, \cdots\} ,表示 n = \prod p_i ^ {c_i} ,其中 p_i 为第 i 个质数。因为 x\mid y 等价于 x 的每个质因数的幂次不大于 y 的该质因数的幂次,即 \forall i, a_x(i) \leq a_y(i) ,那么 n 的所有因数就是所有使得 0\leq a_d(i) \leq a_n(i) 的 d 。
以上分析结合乘法原理和唯一分解定理可以推出因数个数公式 d(n) = \prod (c_i + 1) 。
因此,f * 1 可以看成对下标做关于其无穷序列的高维前缀和,即
g(n) = \sum_{\forall i, a_d(i) \leq a_n(i)} f(d).
根据高维前缀和,枚举每一维并将所有下标关于该维做前缀和,得到狄利克雷前缀和算法:
初始令 x_i = f(i) 。
按任意顺序枚举每个维度,即按任意顺序枚举不超过 n 的质数 p_i 。
按当前维度从小到大的顺序,将每个下标贡献至当前维度加 1 之后的对应下标,即从小到大枚举 k\in [1, \frac n {p_i}] ,将 x_{p_ik} 加上 x_k 。
最终 x 即为 g 。
因为小于 n 的素数倒数和为 \mathcal{O}(\log\log n) ,所以算法时间 \mathcal{O}(n\log\log n) 。
模板题 代码。
#include <bits/stdc++.h>
using namespace std;
constexpr int N = 2e7 + 5;
int n;
unsigned ans, a[N], seed;
inline unsigned rd() {
seed ^= seed << 13, seed ^= seed >> 17, seed ^= seed << 5;
return seed;
}
bool vis[N];
int cnt, pr[N >> 3];
void sieve() {
for(int i = 2; i <= n; i++) {
if(!vis[i]) pr[++cnt] = i;
for(int j = 1; j <= cnt && i * pr[j] <= n; j++) {
vis[i * pr[j]] = 1;
if(i % pr[j] == 0) break;
}
}
}
int main() {
cin >> n >> seed, sieve();
for(int i = 1; i <= n; i++) a[i] = rd();
for(int i = 1; i <= cnt; i++) {
for(int j = 1; j * pr[i] <= n; j++) {
a[j * pr[i]] += a[j];
}
}
for(int i = 1; i <= n; i++) ans ^= a[i];
cout << ans << endl;
return 0;
}3. 数论分块
数论分块又称整除分块,解决下标带有整除值的和式。最基本的和式形如
\sum_{i = 1} ^ n f(i) g\left(\left\lfloor \frac n i\right\rfloor\right).
数论分块的核心结论是 n 的不同整除值的数量级为 \sqrt n 。本小节将从该结论出发,介绍数论分块的基本算法以及各种扩展,如向上取整的数论分块,高维数论分块等。数论分块也是高级筛法的前置要求。
3.1 算法介绍
定义(整除值)
首先考虑求和式:
\sum_{i = 1} ^ n f(i) g\left(\left\lfloor \frac n i\right\rfloor\right).
注意求和上指标与取整式的被除数相等。本节最后会讨论不相等的情况。
我们只关心 g 在所有 n 的整除值处的取值。如果整除值的数量不多,且 f 的前缀和可以快速计算,则可以转换贡献形式,将原式写成若干个 g(\lfloor \frac n i\rfloor) 乘以一段 f 的和。
当 i 较大时,\lfloor \frac n i\rfloor 被限制在较小范围内,大部分相同。结合 \min(i, \frac n i) \le \sqrt n ,可以想到根号分治。
结论(整除值的数量)
**证明**
当 $i \leq \sqrt n$ 时,因为 $i$ 只有 $\lfloor \sqrt n \rfloor$ 个,所以 $\lfloor \frac n i\rfloor$ 只有不超过 $\lfloor \sqrt n \rfloor$ 个不同的取整。
当 $i > \sqrt n$ 时,因为 $\lfloor \frac n i\rfloor \leq \sqrt n$,所以 $\lfloor \frac n i\rfloor$ 也只有不超过 $\lfloor \sqrt n \rfloor$ 个不同的取值。
根据该结论,枚举 \mathcal{O}(\sqrt n) 种整除值 d ,求出最小和最大的 i 使得 \lfloor \frac n i \rfloor = d ,分别记为 l, r ,则原式可写为
\sum_{d} g(d) \sum_{i = l} ^ r f(i).
还剩一个问题:如何不重不漏地考虑所有整除值 d ,并算出其对应的极长区间 [l, r] ?
结论
给定 d ,使得 \lfloor \frac n i\rfloor \geq d 的最大的正整数 i 为 \lfloor \frac n d\rfloor 。
证明
因为 d 都是正整数,所以 \lfloor \frac n i\rfloor \geq d 当且仅当 \frac n i\geq d ,当且仅当 i\leq \frac n d 。
因此,给定整除值 d ,\lfloor \frac n i\rfloor = d 要求 \lfloor \frac n i\rfloor \geq d 且 \lfloor \frac n i\rfloor < d + 1 ,即 \lfloor \frac n {d + 1}\rfloor < i \leq \lfloor \frac n d\rfloor 。
考虑 从小到大枚举所有极长区间 。因为 \lfloor \frac n x\rfloor 随着 x 增大而单调不增,所以相当于 从大到小枚举整除值 。第一个整除值是 n ,对应 l = r = 1 。第二大的整除值对应的 l 为 2 ,由此算出整除值 \lfloor \frac n 2\rfloor ,继而由上述结论算出对应的 r 。
一般地,给定整除值 d 和对应的 [l, r] ,如果 d\neq 1 ,那么下一个(比它小的最大的)整除值 d' 对应的区间的左端点 l' 等于 r + 1 ,从而算出整除值 d' \gets \lfloor \frac n {l'}\rfloor 和对应的 r'\gets \lfloor \frac n {d'}\rfloor = \left \lfloor \frac n {\lfloor n / l'\rfloor}\right\rfloor 。注意:区间右端点一定是整除值 。
从下图可以看出,随着 x 增大,整除值以及对应区间的变化:当前整除值的下一个整除值是 \lfloor \frac n {r + 1} \rfloor ,对应区间的左端点是 r + 1 。
>
若 O(1) 计算 g 和 f 的前缀和在单个整除值处的取值,则算法的时间复杂度为 \mathcal{O}(\sqrt n) 。
特别地,当求和上指标(记为 m )不等于被除数 n 的时候,和式形如 \sum_{i = 1} ^ m f(i) g(\lfloor \frac n i\rfloor) 。
为了处理 n > m 的情况,r 应与 m 取较小值。
为了处理 n < m 的情况,当 \lfloor \frac n i\rfloor = 0 时,直接令 r\gets m 。
结论(整除值的结构)
小于 \sqrt n 的整除值是小于 \sqrt n 的所有正整数,不小于 \sqrt n 的整除值是所有 \lfloor \frac n i\rfloor ,其中 i 是不超过 \sqrt n 的正整数。
3.2 扩展问题
数论分块的算法框架简单,有多种变形。
3.2.1 向上取整
将和式中的向下取整改成向上取整。
同样地,\lceil \frac n x\rceil 随着 x 增大而单调不增,所以算法框架不变,依然是从小到大考虑每段区间。只需对左边界 l 求出使得 \lceil\frac n l \rceil = \lceil\frac n r \rceil 的最大的 r 。
设 k = \lceil\frac n l\rceil ,则要求 \frac n r > k - 1 。
\dfrac n r > k - 1 \iff r < \dfrac{n}{k - 1} \iff r\leq \left\lfloor\frac{n - 1}{k - 1}\right\rfloor.
第二步的依据是 n, k, r 均为正整数。因此,令 r\gets \lfloor\frac{n - 1}{k - 1}\rfloor 即可。
注意特判 k = 1 的情况,此时 r 需要取实际上界。
3.2.2 高维数论分块
当和式有若干下取整,形如
\sum_{i = 1} ^ n \left(f(i) \prod_{j = 1} ^ c g_i\left(\left\lfloor \dfrac {n_j} {i}\right\rfloor\right)\right)
时,只需稍作修改,令
r \gets \min\left(n, \min_{j = 1} ^ c\left\lfloor \frac {n_j} {\lfloor \frac {n_j} l\rfloor}\right\rfloor\right),
也就是取所有 n_j 的下一个 “断点” 中最小的那个。
忽略 f 和 g_i 的计算,时间 \mathcal{O}(\sum \sqrt {n_j}) 。
称存在 n_j 满足 \lfloor \frac {n_j} {i}\rfloor \neq \lfloor \frac {n_j} {i + 1}\rfloor 的 i 为断点,则总断点数量为每个下取整式的断点数量相加(而不是相乘)。在相邻两个断点之间,对每个 n_j ,所有 \lfloor \frac {n_j} i\rfloor 都是相等的。
3.2.3 数论分块嵌套
数论分块的嵌套,即对外层数论分块的每个整除值 d ,内层还要做规模为 d 的数论分块。常见于计算 g(\lfloor \frac n i \rfloor) 需要数论分块的情况,如第四章例题 P5518 的最后一部分。
写起来和普通数论分块一样,核心在于时间复杂度分析:
对小于 \sqrt n 的整除值,贡献为 \int_1 ^ {\sqrt n} \sqrt {x} \mathrm{d} x = \Theta(n ^ {\frac 3 4}) 。
对大于 \sqrt n 的整除值,贡献为 \int_1 ^ {\sqrt n} \sqrt n x ^ {-\frac 1 2} \mathrm{d} x = \Theta(n ^ {\frac 3 4}) 。
结论(整除值的根号和)
所有整除值的根号和在 n ^ {3 / 4} 级别。
杜教筛的复杂度分析也用到了该结论。
我们还得到了一个有趣的结论:n 的小于 \sqrt n 和大于 \sqrt n 的整除值的根号和是同阶的,虽然后者严格比前者大。算出积分,前者系数为 \frac 2 3 ,后者系数为 2 ,差了大约三倍。
3.3 例题
更多例题见第五章莫比乌斯反演。
[模拟赛] 你还没有卸载吗
给定 A_1, B_1, A_2, B_2, N ,求有多少 x\in [1, N] 使得 B_1 + \lfloor\frac{A_1}{x}\rfloor = B_2 + \lfloor\frac{A_2}{x}\rfloor 。
直接二维数论分块即可。时间 \mathcal{O}(\sqrt V) 。
另解
考虑数论分块 [l, r] 固定整除值 \frac{A_1} x 解出 d = \frac{A_2}{x} ,反推出 x 的范围 [l, r] \cap [\frac{A_2}{d + 1} + 1, \frac{A_2}{d}] 。
#include <bits/stdc++.h>
using namespace std;
int T, a1, b1, a2, b2, n;
int main() {
cin >> T;
while(T--) {
int ans = 0;
cin >> a1 >> b1 >> a2 >> b2 >> n;
for(int l = 1, r = 1; l <= n; l = r + 1) {
r = min(n, min(a1 / l ? a1 / (a1 / l) : n, a2 / l ? a2 / (a2 / l) : n));
if(b1 + a1 / l == b2 + a2 / l) ans += r - l + 1;
}
cout << ans << endl;
}
return 0;
}P2260 [清华集训 2012] 模积和
求 \sum_{i = 1} ^ n n \bmod i 是经典问题:拆成 \sum_{i = 1} ^ n (n - \lfloor\frac n i\rfloor i) 后数论分块,时间复杂度 \mathcal{O}(\sqrt n) 。
原式变形为
\left(\sum_{i = 1} ^ n n\bmod i\right) \left(\sum_{i = 1} ^ m m\bmod i\right) - \sum_{i = 1} ^ {\min(n, m)} \left(n - \left\lfloor\dfrac n i \right\rfloor i\right)\left(m - \left\lfloor\dfrac m i\right\rfloor i \right).
使用数论分块解决。
你可能需要:
\sum_{i = 1} ^ n i ^ 2 = \frac {n(n + 1)(2n + 1)} 6.
时间 \mathcal{O}(\sqrt n) 。代码。
*P3579 [POI2014] PAN-Solar Panels
不错的题目。
当 \lfloor\frac {a - 1} k\rfloor < \lfloor\frac b k\rfloor 且 \lfloor\frac{c - 1} k\rfloor < \lfloor\frac d k\rfloor 时,[a, b] 和 [c, d] 均含有 k 的倍数。答案为所有这样的 k 的最大值。
我们当然可以四维数论分块,但注意到在使得 \lfloor\frac b k \rfloor 相同且 \lfloor \frac d k\rfloor 相同的 k 的区间 [l, r] 当中,选择 k = r 可以使 \lfloor \frac{a - 1} k\rfloor 和 \lfloor \frac {c - 1} k\rfloor 尽可能小,更有机会满足要求。若 k = r 都不满足条件,则 l\leq k \leq r 均不满足条件。因此二维数论分块即可。
时间 \mathcal{O}(T\sqrt V) 。代码。
*CF1603C Extreme Extension
数论分块优化 DP。
一个数如何分裂由后面分裂出来的数的最小值决定,所以贪心使分出来的数尽量均匀。例如,若 9 要分裂为若干个比 4 小的数,那么 3, 3, 3 比 2, 3, 4 更优。
从后往前考虑。对每个位置 i 和值 j\in [1, a_i] ,求出有多少以位置 i 开头的子段根据上述贪心策略分裂出的最小值为 j (j 由 a_i 分裂零次或若干次得到),记为 f_{i, j} 。
考虑 f_{i + 1, j} 往前转移,需要将 a_i 分裂成若干不超过 j 的数,最少需要分裂成 \lceil \frac {a_i} j \rceil 个数。新的最小值是多少?将 a_i 分裂成 c 个数,这些数最小值的最大值为 \lfloor \frac {a_i} c \rfloor 。
注意到,对于固定的分裂次数,分裂出的值也是确定的。考虑枚举使得分裂次数相同的区间 [l, r] ,即 a_i 整除 [l, r] 内所有数向上取整的结果相同,可以通过向上取整的数论分块实现。
设 c = \lceil \frac {a_i} l \rceil 表示分裂出的数的个数,则分裂出的数的最小值为 v = \lfloor \frac {a_i} c \rfloor 。\sum_{j = l} ^ r f_{i + 1, j} 转移到 f_{i, v} 。
考虑在每个位置处统计该位置在所有子段中的总分裂次数之和,则贡献为 i\times (c - 1) \times f_{i , v} 。其含义为,共有 f_{i, v} 个以 i 开头的子段使得 a_i 要分裂出 c 个数,即分裂 c - 1 次。同时,若子段 [i, k] 在 i 处分裂 c - 1 次,则对于任意子段 [x, k] 满足 1\leq x\leq i ,a_i 分裂的次数都是 c - 1 ,因为 a_i 的分裂不受前面的数的影响。
注意,当 c = 1 时,f_{i, v} 即 f_{i, a_i} 需要加 1 ,表示新增以 a_i 结尾的子段。
用 vector 存储所有 f_i 并转移,时间 \mathcal{O}(n\sqrt {a_i}) 。滚动数组优化后空间 \mathcal{O}(n) 。代码。
4. 欧拉函数
欧拉函数是非常重要的数论函数。
4.1 定义与性质
首先我们肯定希望 $\varphi$ 是积性函数。
> **性质 1(积性函数)**
>
> $\varphi$ 是积性函数。
>
> **证明**
>
> 设 $n\perp m$。
>
> 可以证明 $(i, j)$ 和 $k$ 构成双射(证明如下),其中 $i, j, k$ 分别和 $n, m, nm$ 互质,则 $\varphi(nm) = \varphi(n)\varphi(m)$。
>
> 因为 $n\perp m$,由中国剩余定理(同余理论第三章),若 $k\neq k'$,则它们模 $n$ 和模 $m$ 的余数不完全相等。于是只需证明 $k \perp nm$ 当且仅当 $k$ 模 $n$ 和模 $m$ 分别和 $n, m$ 互质,这是平凡的。$\square
另一种证明
设与 n 互质的数为 a_{1\sim \varphi(n)} ,那么在 [0, nm - 1] 内与 n 互质的数为 jn + a_i ,其中 1\leq i \leq \varphi(n) ,0\leq j < m 。
因为 n\perp m ,所以 jn 在模 m 下互不相同,否则 (j - j')n 是 m 的倍数,可知 j\equiv j'\pmod m ,矛盾。
因此,对每个 a_i ,(jn + a_i)\bmod m 取遍 0\sim m - 1 ,其中有 \varphi(m) 个和 m 互质。
在 [0, nm - 1] 内共有 \varphi(n)\varphi(m) 个数同时和 n, m 互质(于是和 nm 互质)。\square
因为 \varphi 是积性函数,所以只需考虑其在质数幂处的取值。
性质 2
设 p 是质数,则 \varphi(p ^ k) = (p - 1)p ^ {k - 1} 。
证明
因为 p 是质数,所以和 p 不互质当且仅当是 p 的倍数,共有 p ^ {k - 1} 个。\square
根据性质 2 可线性筛欧拉函数。写成 \varphi(p) = p - 1 ,\varphi(p ^ k) = p\varphi(p ^ {k - 1})\ (k\geq 2) ,方便线性筛。
int cnt, pr[N], phi[N], vis[N];
void sieve() {
phi[1] = 1;
for(int i = 2; i < N; i++) {
if(!vis[i]) pr[++cnt] = i, phi[i] = i - 1;
for(int j = 1; j <= cnt && i * pr[j] < N; j++) {
vis[i * pr[j]] = 1;
phi[i * pr[j]] = (pr[j] - 1) * phi[i];
if(i % pr[j] == 0) {
phi[i * pr[j]] = pr[j] * phi[i];
break;
}
}
}
}性质 1 和性质 2 给出了直接计算欧拉函数的公式。
性质 3(计算欧拉函数)
设 n 的唯一分解为 \prod_{i = 1} ^ m p_i ^ {c_i} ,则
\varphi(n) = n\times \prod_{i = 1} ^ {m} \frac {p_i - 1} {p_i}.
int phi(int x) {
int ans = x;
for(int i = 2; i * i <= x; i++)
if(x % i == 0) {
while(x % i == 0) x /= i;
ans = ans / i * (i - 1);
}
return ans / x * max(1, x - 1);
}计算 \varphi(n) 的时间是分解质因数的 \mathcal{O}(\sqrt n) ,使用 Pollard-Rho 算法可以做到 \mathcal{O}(n ^ {1 / 4}) 。
欧拉函数的计算式也可以通过容斥原理证明。
证明
根据容斥原理,去掉所有被至少一个 n 的质因数整除的数,加上至少被两个 n 的质因数整除的数,以此类推,最终得到
\varphi(n) = n \sum_{T\subseteq S} \frac {(-1) ^ {|T|}}{\prod_{p\in S} p}
其中 S 是 n 的质因数集合。上式是 n \prod_{i = 1} ^ m (1 - \frac 1 {p_i}) 的直接展开。\square
根据上式推出性质 1 和性质 2 是平凡的。
接下来给出一些常用的欧拉函数的性质。
性质 4
若 n\mid m ,则 \varphi(nm) = n\varphi(m) 。
证明
直观理解 :因为 nm 相较 m 没有增加质因数,所以原来与 m 互质的数仍与 nm 互质。[0, nm - 1] 当中与 m 互质的数的个数为 n\varphi(m) ,因为一个与 m 互质的数加上 m 的倍数后仍然与 m 互质。
容易发现 n\mid m 的条件可弱化为 m 含有 n 的所有质因数。在考虑互质的时候,质因数的幂次是不重要的,只有质因数集合是重要的。
性质 5
对 n \geq 3 ,2\mid \varphi(n) 。
证明
若 x \perp n ,则 n - x\perp n 。所有小于 n 且与 n 互质的数能一一配对。
x = n - x$ 是特例,此时 $x = \frac n 2$,$\gcd(x, n) = x \neq 1$。$\square
也可以考虑计算式。对于如果只含质因数 2 ,则 \varphi(n) = \frac n 2 是偶数。否则奇质因数 p 的 \frac {p - 1} {p} 将导致 \varphi(n) 是偶数。
性质 6
若 n \mid m ,则 \varphi(n) \mid \varphi(m) 。
回忆同余理论一开始的基本知识:
性质 7
对 d\mid n ,使得 \gcd(n, x) = d 的 x\in [0, n - 1] 的数量为 \varphi(\frac n d) 。
证明
\gcd(n, x) = d$ 要求 $x$ 是 $d$ 的倍数且 $\gcd(\frac n d, \frac x d) = 1$。因为 $\frac x d$ 的范围是 $[0, \frac n d - 1]$,所以 $x$ 的数量为 $\varphi(\frac n d)$。$\square
考虑到 0\sim n - 1 的每个数和 n 的最大公约数都是 n 的因数,得到欧拉反演公式。
性质 8(Euler 反演)
\sum_{d\mid n}\varphi(d) = n.
证明
枚举每个数和 n 的最大公约数 d ,由性质 7,
n = \sum_{d\mid n} \sum_{i = 0} ^ {n - 1} [\gcd(n, i) = d] = \sum_{d\mid n} \varphi\left(\frac n d\right) = \sum_{d\mid n} \varphi(d).
\square
> **定理 9.1(欧拉定理)**
>
> 设 $a\perp n$,则
> $$
> a ^ {\varphi(n)} \equiv 1\pmod n.
> $$
>
> **定理 9.2(扩展欧拉定理)**
> $$
> a ^ b \equiv \begin{cases}
> a ^ {b\bmod \varphi(n)}, & a\perp n; \\
> a ^ b, & a\not\perp n \land b < \varphi(n); \\
> a ^ {(b\bmod \varphi(n)) + \varphi(n)}, & a\not\perp n \land b \geq \varphi(n)
> \end{cases} \pmod n.
> $$
> 关于证明,见 [同余理论](https://www.luogu.com.cn/article/v12gqxap) 第一章。
>
> 当 $a\perp n$ 时,$a ^ {b\bmod \varphi(n)} \equiv a ^ {(b\bmod \varphi(n)) + \varphi(n)}$,于是在使用扩展欧拉定理时,先特判 $b < \varphi(n)$ 的情况,然后用 $a ^ {(b\bmod \varphi(n)) + \varphi(n)}$ 作为结果,无需分讨 $a\perp n$ 的情况。
### 4.2 例题
#### [UVA10179 Irreducable Basic Fractions](https://www.luogu.com.cn/problem/UVA10179)
根据既约分数的定义 $m \perp n$ 且 $0 \leq m < n$,可知答案即 $\varphi(n)$。
#### [UVA11327 Enumerating Rational Numbers](https://www.luogu.com.cn/problem/UVA11327)
样例告诉我们分母不大于 $2\times 10^5$,因此预处理出 $[1,2\times 10^5]$ 每个数的欧拉函数。从小到大枚举分母,求出分母后再根据剩余个数从小到大枚举分子。
#### [P5091 【模板】扩展欧拉定理](https://www.luogu.com.cn/problem/P5091)
$b$ 是高精度,一个比较方便的处理方法是先用字符串存,如果长度不超过 $9$ 则直接转成整型用快速幂算,否则直接算 $a ^ {(b\bmod \varphi(n)) + \varphi(n)}$。
```cpp
#include <bits/stdc++.h>
using namespace std;
int a, mod;
string st;
int ksm(int a, int b) {
int s = 1;
while(b) {
if(b & 1) s = 1ll * s * a % mod;
a = 1ll * a * a % mod, b >>= 1;
}
return s;
}
int Phi(int x) {
int res = x;
for(int i = 2; i * i <= x; i++) {
if(x % i == 0) {
res = res / i * (i - 1);
while(x % i == 0) x /= i;
}
}
if(x > 1) res = res / x * (x - 1);
return res;
}
int main() {
cin >> a >> mod >> st;
if(st.size() <= 9) {
int b = 0;
for(char it : st) b = b * 10 + it - '0';
cout << ksm(a, b) << endl;
return 0;
}
int phi = Phi(mod), b = 0;
for(char it : st) b = (b * 10 + it - '0') % phi; // 因为 phi <= 10 ^ 8,所以不需要 1ll.
cout << ksm(a, b + phi) << endl;
return 0;
}
```
#### *[P4139 上帝与集合的正确用法](https://www.luogu.com.cn/problem/P4139)
> 题意简述:求 $2 ^ {2 ^ {2 ^ {2 ^ {\cdots}}}} \bmod p$,$1 \leq p \leq 10 ^ 7$。
初看这个无限幂塔,有点令人摸不着头脑,因为直觉告诉我们这个值不存在,就好像 $\infty$ 是一个不确定的数一样。但是,当 $x$ 足够大时,$2\uparrow\uparrow x$($x$ 层幂塔)与 $2\uparrow\uparrow (x + 1)$ 在模 $p$ 下相同。
为什么呢?根据扩展欧拉定理,上面的幂塔等于 $2 ^ {(2 ^ {2 ^ {2 ^ {\cdots}}} \bmod \varphi(p) + \varphi(p))}\bmod p$,不断使用扩展欧拉定理得到
$$
\large
2 ^ {\left(2 ^ {\left(2 ^ {\left(2 ^ {\cdots}
\bmod \varphi(\varphi(\varphi(p))) +\varphi(\varphi(\varphi(p)))\right)}
\bmod \varphi(\varphi(p)) + \varphi(\varphi(p))\right)}
\bmod \varphi(p) + \varphi(p)\right)}
\bmod p
$$
因为幂塔会一直延伸下去,所以不需要担心出现 $2 ^ {2 ^ {2 ^ {\cdots}}} < \varphi(mod)$ 的导致不能加 $\varphi(mod)$ 的情况。
又因为 $2\mid \varphi(p),\ \forall p \geq 3$(性质 5)且偶数的欧拉函数不超过其本身的一半,所以 $\varphi(p)$ 的迭代值会指数衰减为 $1$。此时,不用关心往上的幂次是多少了,因为任何数模 $1$ 都得 $0$,这是终止条件。
综上,线性筛出 $p$ 以内所有数的欧拉函数即可做到时间 $\mathcal{O}(p+T\log p)$。
```cpp
int F(int x) { // 计算幂塔模 x.
if(x <= 2) return 0;
int v = phi(x);
return ksm(2, F(v) + v, x); // 2 ^ (F(v) + v) % x
}
```
#### *[P3747 [六省联考 2017] 相逢是问候](https://www.luogu.com.cn/problem/P3747)
根据上一题的结论,$c ^ {c ^ {c ^ {\cdots ^ {a_i}}}} \bmod p$ 在迭代足够多次之后为定值。迭代次数 $cnt$ 为使得 $\varphi(\varphi(\cdots\varphi(\varphi(p))\cdots)) = 1$ 的迭代次数再加 $1$,是 $\mathcal O(\log p)$ 数量级的。为什么要加 $1$ 呢?如果不加 $1$,迭代 $cnt$ 次之后顶上模 $1$ 的数是 $a_i$ 而不是 $c$,当 $a_i = 0$ 时会出问题,导致再迭代一次之后结果改变(例如 $a = 0$,$c = p = 2$)。
预处理每个位置上的幂塔迭代 $0\sim cnt$ 次之后的结果。这样,如果一个位置迭代了 $cnt$ 次,幂塔的值就不会改变了。可以用线段树维护区间内每个位置被迭代次数的最小值,如果该值已经等于 $cnt$,则再迭代一轮也不会影响结果,直接返回。否则暴力递归下去修改。
一个细节是判断指数是否大于等于 $\varphi(p)$。在计算幂塔的时候,除了 $c = 1$ 以外,一旦当前结果大于等于模数,则之后的迭代也大于等于模数(还有 $c = 2$,$p = 6$ 的情况,$2\geq \varphi(6)$ 但 $2 ^ 2 < 6$,但是没法构造卡掉的数据)。因为底是固定的,所以采用光速幂,并记录 $c ^ {lim} \geq p$ 的阈值 $lim$ 方便比较结果和 $p$ 的大小关系。
每个位置预处理 $\mathcal{O}(\log p)$ 个值,每个值迭代 $\mathcal{O}(\log p)$ 次,每次迭代用光速幂 $\mathcal{O}(1)$ 计算。预处理的时间为 $\mathcal{O}(n\log ^ 2 p)$。
查询时每个位置最多被操作 $\mathcal{O}(\log p)$ 次,每次操作花费 $\mathcal{O}(\log n)$ 的时间(因为在线段树上的)。因此,总时间复杂度为 $\mathcal{O}((n\log p + m\log n)\log p)$。
[代码](https://qoj.ac/submission/2036570)。
## 5. 莫比乌斯函数
**前置知识**:容斥原理。
对于数论函数,对因数下标求和是一步很常见的操作,形如 $g(n) = \sum_{d\mid n} f(d)$,即狄利克雷前缀和。有时 $g(n)$ 容易求出,我们需要根据 $g = f * 1$ 反推出原函数 $f = g * 1 ^ {-1}$,这说明 $1$ 的狄利克雷卷积逆也很重要。
### 5.1 定义
#### 5.1.1 引入
考虑这样一个问题:求 $0\sim n - 1$ 有多少个数和 $n$ 互质。读者知道答案是 $\varphi(n)$。接下来我们将从另一个角度求解问题,并引出莫比乌斯函数的定义。
互质即最大公约数等于 $1$。当 “恰好等于” 的限制令我们无从下手时,可以转变思路,使用容斥原理。
在这种因数相关的问题中,我们一般采用 **倍数容斥**,也就是把 “恰好等于 $i$” 改成 “是 $i$ 的倍数”(少量题目中是因数)。这样一来,$0\sim n - 1$ 当中和 $n$ 的最大公约数是 $i$ 的倍数的数的个数是容易计算的:若 $i\nmid d$ 则为 $0$,否则为 $\frac n i$。
用 gcd 是 $1$ 的倍数的数的个数,减去 gcd 是 $2$ 的倍数的数的个数,减去 gcd 是 $3$ 的倍数的数的个数,以此类推。这样,gcd 是 $6$ 的倍数的数被减去了两次,所以贡献还要加回来。问题转化为对每个 “gcd 是 $i$ 的倍数的数的个数” $g(i)$,求出其对应的 **容斥系数** $\mu(i)$。
设 gcd 恰好等于 $i$ 的数的个数为 $f(i)$,则 $g(i) = \sum_{i\mid d} f(d)$ 且答案为 $f(1) = \sum_{i = 1} ^ n g(i)\mu(i)$。
#### 5.1.2 推导
> **推法 1**
>
> 考虑将 $f$ 和 $g$ 之间的关系写成狄利克雷卷积的形式,但目前的和式 $g(i) = \sum_{i\mid d} f(d)$ 是对倍数下标而非因数下标求和。
>
> 本题中,只有 $n$ 的因数的下标是重要的。因此,考虑将 $f$ 和 $g$ 的下标 “翻转”,即 $i\to \frac n i$。这样,$f(i)$ 表示 gcd 是 $\frac n i$ 的数的个数,$g(i)$ 表示 gcd 是 $\frac n i$ 的倍数的数的个数,则 $g(i) = \sum_{d\mid i} f(d)$ 且答案为 $f(n) = \sum_{i \mid n} g(\frac n i) \mu(i)$。
>
> 于是 $g = f * 1$,可知 $f = g * 1 ^ {-1}$,再结合答案式可知 $\mu = 1 ^ {-1}$。
> **推法 2**
>
> 将容斥原理用到底。
>
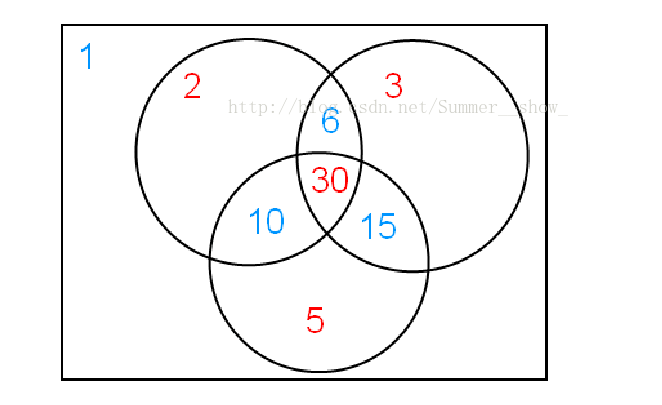
> $f(1)$ 等于 $f$ 在 $1$ 的倍数处的取值和 $g(1)$,减去在质数倍数处的取值和 $\sum g(p_i)$。但是这样多减去了两个不同质数乘积的倍数处的取值和 $\sum g(p_ip_j)$,所以要加上这些值。但是这样又多加上了在三个不同质数乘积的倍数处的取值和 $\sum g(p_ip_jp_k)$,所以要减去这些值,以此类推。如图([图源](https://blog.csdn.net/Summer__show_/article/details/76269088))。
>
> 
>
> 若 $n$ 为 $k$ 个不同质数的乘积,则容斥系数为 $\mu(n) = (-1) ^ k$。
>
> 在固定了所有无平方因数数的容斥系数的基础上,考虑 $n$ 存在质因数幂次 $c_i > 1$ 的情况。此时 $f(n)$ 的贡献系数与将所有幂次 $c_i$ 变成 $1$ 之后的 $n'$ 的 $f(n')$ 的贡献系数相等,后者已知等于 $0$(容斥原理),所以 $f(n)$ 无贡献,自然不必加减 $g(n)$,即 $\mu(n) = 0$。
> **推法 3**
>
> 更具体地推系数。
>
> - $f(1)$ 对答案的贡献系数为 $1$,但现在贡献为 $0$,少加了一次,而 $g(1)$ 是唯一含有 $f(1)$ 的项,所以加上 $g(1)$,且系数 $\mu(1)$ 只能等于 $1$。
> - $f(2)$ 对答案的贡献系数为 $0$,但现在贡献为 $\sum_{i \mid 2\land i \neq 2} \mu(i) = \mu(1) = 1$,多加了一次,而 $g(2)$ 是除了系数已经不能动的 $g(1)$ 以外唯一含有 $f(2)$ 的项,所以减去 $g(2)$,且系数 $\mu(2)$ 只能等于 $-1$。
> - $f(3)$ 对答案的贡献系数为 $0$,但现在贡献为 $\sum_{i \mid 3\land i \neq 3} \mu(i) = \mu(1) = 1$,多加了一次,而 $g(3)$ 是除了系数已经不能动的 $g(1)$ 以外唯一含有 $f(3)$ 的项,所以减去 $g(3)$,且系数 $\mu(3)$ 只能等于 $-1$。
> - $f(4)$ 对答案的贡献系数为 $0$,但现在贡献为 $\sum_{i \mid 4\land i \neq 4} \mu(i) = \mu(1) + \mu(2) = 0$,刚好。而 $g(4)$ 是除了系数已经不能动的 $g(1)$ 和 $g(2)$ 以外唯一含有 $f(4)$ 的项,所以 $g(4)$ 的系数 $\mu(4)$ 只能等于 $0$。
>
> 以此类推,对 $n > 1$ 有递推关系 $\mu(n) = -\sum_{d\mid n \land d\neq n} \mu(d)$,这正是 $1$ 的狄利克雷卷积逆。
还需要计算 $1 ^ {-1}$ 从而将推法 1、3 和推法 2 联系在一起。
> **计算 $1 ^ {-1}$**
>
> 设 $\mu = 1 ^ {-1}$,则因为 $1$ 是积性函数,所以 $\mu$ 是积性函数,只需观察其在所有质数倍数处的取值。根据递推关系
> $$
> \mu(n) = -\sum_{d\mid n \land d\neq n} \mu(d),
> $$
> 可得
> $$
> \begin{aligned}
> \mu(p) & = -\mu(1) = -1; \\
> \mu(p ^ 2) & = -(\mu(1) + \mu(p)) = 0; \\
> \mu(p ^ 3) & = -(\mu(1) + \mu(p) + \mu(p ^ 2)) = 0.
> \end{aligned}
> $$
> 容易归纳证明当 $k \geq 2$ 时,$\mu(p ^ k) = 0$。
>
> 设唯一分解 $n = \prod_{i = 1} ^ m p_i ^ {c_i}$。根据 $\mu$ 的积性,若存在 $c_i\geq 2$ 则 $\mu(n) = 0$,否则 $\mu(n) = (-1) ^ m$。
#### 5.1.3 总结
为了从 “倍数下标的取值和” $g(n)$ 得到 $f(1) = \sum_{i = 1} ^ n g(i)\mu(i)$,容斥系数(相当于对 “是质数 $p_i$ 的倍数” 的关系做容斥)应等于
$$
\mu(n) =
\begin{cases}
0, & \exists d > 1, d ^ 2\mid n; \\
(-1) ^ {\omega(n)}, & \mathrm{otherwise}.
\end{cases}
$$
这个函数是 $1$ 的狄利克雷卷积逆,称为 **莫比乌斯函数**。
我们可以直接验证 $\mu * 1 = \epsilon$:考虑 $n$ 的所有质因数 $p_{1\sim m}$。对于任意 $k$ 个质因数的乘积 $P$,它产生 $\mu(P) = (-1) ^ k$ 的贡献。枚举 $k$,则由二项式定理,
$$
(\mu * 1)(n) = \sum_{k = 0} ^ m \binom m k (-1) ^ k = [m = 0] = [n = 1].
$$
上述做法可以扩展到求 $\sum_{i = 0} ^ {m - 1} [i\perp n]$。它给出了一般化的结论:已知数论函数 $f$ 的倍数下标的和,计算 $f(1)$ 时,每个位置的贡献系数为莫比乌斯函数。
> **结论 1($\varphi = id * \mu$)**
>
> 回到原来的问题,求 $0\sim n - 1$ 有多少个数和 $n$ 互质。
>
> 采用推法 1 的翻转下标技巧:$f(i)$ 表示 gcd 是 $\frac n i$ 的数的个数,$g(i)$ 表示 gcd 是 $\frac n i$ 的倍数的数的个数,则 $g(i) = \sum_{d\mid i} f(d)$ 且答案为 $f(n) = \sum_{i \mid n} g(\frac n i) \mu(i)$。
>
> 我们知道 $g(i) = i$ 且 $f(i) = \varphi(i)$,所以 $g(i) = \sum_{d\mid i} f(d)$ 说明 $\mathrm{id} = 1 * \varphi$,$f(n) = \sum_{i \mid n} g(\frac n i) \mu(i)$ 说明 $\varphi = \mathrm{id} * \mu$,即
> $$
> \varphi(n) = \sum_{d\mid n} \frac n d \mu(d).
> $$
> 翻转下标之后可以写成狄利克雷卷积,$f\to g$ 是卷 $1$,所以 $g\to f$ 是卷 $\mu$。
### 5.2 狄利克雷差分
据定义,可线性筛出莫比乌斯函数。
```cpp
int vis[N], cnt, pr[N], mu[N];
void sieve() {
mu[1] = 1;
for(int i = 2; i < N; i++) {
if(!vis[i]) pr[++cnt] = i, mu[i] = -1;
for(int j = 1; j <= cnt && i * pr[j] < N; j++) {
vis[i * pr[j]] = 1;
if(i % pr[j] == 0) break; // i * pr[j] 含至少两个 pr[j], mu = 0
mu[i * pr[j]] = -mu[i]; // mu[i * pr[j]] = mu[i] * mu[pr[j]] = -mu[i]
}
}
}
```
当时间可以接受时,根据 $\mu$ 的求逆递推式 $\mathcal{O}(n\log n)$ 递推更方便。
```cpp
int mu[N];
void sieve() {
mu[1] = 1;
for(int i = 1; i < N; i++) { // 枚举因数变成枚举倍数, 注意枚举顺序
for(int j = i + i; j < N; j += i) {
mu[j] -= mu[i];
}
}
}
```
我们知道数论函数卷 $1$ 是狄利克雷前缀和,那么卷 $\mu$ 就是前缀和的逆操作,即 **狄利克雷差分**。将代码的 `mu` 替换为 `f`,相当于将 $f$ 除以 $1$,即 $f \gets f * \mu$。
```cpp
void PrefixSum(int *f) {
for(int i = N - 1; i; i--) {
for(int j = i + i; j < N; j += i) {
f[j] += f[i];
}
}
}
void Differential(int *f) {
for(int i = 1; i < N; i++) {
for(int j = i + i; j < N; j += i) {
f[j] -= f[i];
}
}
}
```
**注意前缀和和差分的外层枚举顺序**,需要从实际意义理解代码:已知 $g_n = \sum_{d\mid n} f_d$,要求 $f$。考虑递推,假设 $f_{1\sim n - 1}$ 已知(所以枚举最外层的 $i$ 是从小到大),则 $f_n$ 等于 $g_n$ 减去 $n$ 的所有不是它本身的因数的 $f$ 值,即 $f_n = g_n - \sum_{d\mid n\land d\neq n} f_d$。枚举因数不方便,改为枚举倍数,提前减掉贡献(枚举 $i$ 时已经算出 $f_i$)。
实际上 **狄利克雷后缀和** 更常见,也就是我们在引入中看到的例子。将 $f$ 从狄利克雷后缀和当中还原出来也很简单,假设 $f_{n + 1\sim N}$ 已知,从后往前递推 $f_n = g_n - \sum_{n\mid d \land d\neq n} f_d$ 即可。
```cpp
void Differential(int *f) {
for(int i = N - 1; i; i--) {
for(int j = i + i; j < N; j += i) {
f[i] -= f[j]; // 注意是 i 减 j
}
}
}
```
### 5.3 莫比乌斯反演
#### 5.3.1 算法介绍
什么是 [反演](https://vfleaking.blog.uoj.ac/slide/87#/)?给定 $g_i = \sum_{j = 1} ^ n a_{i, j} f_j$,已知 $g$ 求 $f$ 的过程称为反演。
反演本质上是矩阵求逆,即若 $g = Af$ 则 $f = A ^ {-1}g$,其中 $f, g$ 都是向量,$A$ 是系数矩阵。显然,最朴素的做法是直接算出 $A ^ {-1}$,然后将矩阵和向量乘起来。当然,我们在 OI 中学习的各种反演会根据 $A$ 的特殊性质,更高效地计算 $A ^ {-1}g$,毕竟矩阵求逆本身需要 $\mathcal{O}(n ^ 3)$。例如,二项式反演是直接给出 $A ^ {-1}$ 的代数表示。这样,如果只算 $f$ 的一个位置,则只需要 $\mathcal{O}(n)$ 的时间。
最基本的 **莫比乌斯反演** 是狄利克雷前缀和的形式,但后缀和形式有更多的实际应用。
- **前缀和**:若 $g(n) = \sum_{d\mid n} f(d)$,则 $f(n) = \sum_{d\mid n} g(d)\mu(\frac n d)$。可以理解为 $g = f * 1$,$f = g * \mu$。
- **后缀和**:若 $g(n) = \sum_{n\mid d} f(d)$,则 $f(n) = \sum_{n\mid d} g(d) \mu(\frac d n)$。可以理解为 $\mu$ 作为倍数容斥的系数。
当然,更常见的(也是广泛认为的)莫反是 **$\mu$ 作容斥系数在代数形式下的推导技巧**,可以类比 “组合意义天地灭,代数推导保平安”。我们举一个最简单的例子:考虑狄利克雷后缀和。根据之前用各种方法推导出的结论,
$$
\begin{aligned}
f(1) = \sum_{i = 1} ^ n g(i)\mu(i).
\end{aligned}
$$
用代数形式的推导技巧,就是
$$
\begin{aligned}
f(1) & = \sum_{i = 1} ^ n f(i) [i = 1] \\
& = \sum_{i = 1} ^ n f(i) \epsilon(i) \\
& = \sum_{i = 1} ^ n f(i) \cdot (1 * \mu)(i) \\
& = \sum_{i = 1} ^ n f(i) \sum_{d\mid i} \mu(d) \\
& = \sum_{d = 1} ^ n \mu(d) \sum_{d\mid i} f(i) \\
& = \sum_{d = 1} ^ n \mu(d) g(d). \\
\end{aligned}
$$
简单来说就是把 $[n = 1]$ 写成 $\sum_{d\mid n} \mu(d)$,用和式代替艾佛森括号。
> 用和式代替判断式是一个重要的解题技巧,但这个过程并不直观,导致初学者难以上手。例如对于奇质数 $p$ 有
> $$
> \sum_{x = 1} ^ {p - 1} [x ^ 2 = a] = (a ^ {\frac{p - 1} 2} \bmod p) + 1,
> $$
> 单位根反演
> $$
> [n\mid a] = \frac 1 n\sum_{i = 0} ^ {n - 1} \omega_n ^ {ia}.
> $$
> 从判断式到和式的过程逐渐形成了套路,了解其背后的逻辑有助于读者掌握并运用这种套路。
以上其实就是莫反的全部内容了,它是一个比较吃熟练度的知识点,需要多做题。我们将从众多例题当中感受到莫反的广泛应用。
#### 5.3.2 结论与技巧
本小节介绍几个莫反相关的系统性套路。
最常见的套路是 $[i\perp j]$ 转化为枚举 $d\mid \gcd(i, j)$ 并对 $\mu(d)$ 求和,这样可以先枚举 $d$,此时 $i, j$ 独立。
> **结论 1**
>
>
> $$
> \begin{aligned}
> & \sum_{i = 1} ^ n \sum_{j = 1} ^ m [i\perp j] \\
> = \, & \sum_{i = 1} ^ n \sum_{j = 1} ^ m [\gcd(i, j) = 1] \\
> = \, & \sum_{i = 1} ^ n \sum_{j = 1} ^ m \sum_{d\mid \gcd(i, j)} \mu(d) \\
> = \, & \sum_{d = 1} ^ {\min(n, m)} \mu(d) \sum_{i = 1} ^ n \sum_{j = 1} ^ m [d\mid i][d\mid j] \\
> = \; & \sum_{d = 1} ^ {\min(n, m)} \mu(d) \left\lfloor \dfrac n d \right\rfloor \left\lfloor \dfrac m d \right\rfloor.
> \end{aligned}
> $$
> 显然,实际含义是对 “最大公约数是 $n$ 的倍数” 的 $(i, j)$ 对数量做倍数容斥。
> **结论 2**
>
> 因为 $\varphi * 1 = \mathrm{id}$,所以 $\mathrm{id} * \mu = \varphi$,即
> $$
> \sum_{d \mid n} \frac {n\mu(d)} d = \varphi(n).
> $$
>
>
> 变式为
> $$
> \sum_{d\mid n} \frac{\mu(d)} d = \frac {\varphi(n)} n.
> $$
> **结论 3**
> $$
> d(ij) = \sum\limits_{x \mid i}\sum\limits_{y\mid j} [x\perp y].
> $$
> 考虑单个质因数 $p$,再用中国剩余定理合并,即不同质因数的贡献相乘。
>
> 设 $a = v_p(i)$ 即 $i$ 含质因数 $p$ 的数量,$b = v_p(j)$,则 $v_p(ij) = a + b$。对于 $ij$ 的约数 $d$,若 $v_p(d) \leq a$,则令其对应 $v_p(x) = v_p(d)$,$v_p(y) = 0$;若 $v_p(d) > a$,则令其对应 $v_p(x) = 0$,$v_p(y) = v_p(d) - a$。容易发现互质对 $(x, y)$ 和 $d$ 之间形成双射,因此 $d$ 就等于 $[x\perp y]$ 的对数。
>
> 简单来说就是
> $$
> (a, 0), (a - 1, 0), \cdots, (1, 0), (0, 0), (0, 1), \cdots, (0, b - 1), (0, b)
> $$
> 一共 $a + b + 1$ 对,和 $d(ij)$ 当中质因数 $p$ 的贡献系数 $(a + b + 1)$ 一致。
>
> 例题:P3327。
> **结论 4**
> $$
> \begin{aligned}
> & \sum_{i = 1} ^ N \gcd(k, i) \\
> = \; & \sum_{d \mid k} d \sum_{i = 1} ^ {\frac N d} \left[\frac k d\perp i\right] \\
> = \; & \sum_{d \mid k} d \sum_{d'\mid \frac k d} \mu(d') \sum_{i = 1} ^ {\frac N d} [d'\mid i] \\
> = \; & \sum_{d \mid k} d \sum_{d' \mid \frac k d} \mu(d') \left\lfloor \frac {N} {dd'} \right\rfloor \\
> = \; & \sum_{T \mid k} \left\lfloor\frac {N} {T}\right\rfloor \sum_{d\mid T} d \mu\left(\frac T d\right) \\
> = \; & \sum_{T \mid k} \left\lfloor\frac {N} {T}\right\rfloor \varphi(T).
> \end{aligned}
> $$
> 以上推导过程用到了莫反推式子时的常用技巧:将枚举的两个约数 $d\mid n$ 和 $d'\mid \frac n d$ 乘起来,枚举乘积 $T = dd'$,通常会带来奇妙的化学反应。
>
> 另一种推法是用 $\mathrm{id} = 1 * \varphi$ 将 $\gcd(i, k)$ 写成 $\sum_{d \mid \gcd(i, k)} \varphi(d)$,枚举 $d$,则 $d$ 需要是 $k$ 的因数,且 $i$ 需要是 $d$ 的倍数,这样的 $i$ 共有 $\lfloor \frac N d\rfloor$ 个。
### 5.4 例题
除特殊说明外,所有分式默认向下取整。
#### [P2522 [HAOI2011] Problem b](https://www.luogu.com.cn/problem/P2522)
二维差分将下界化为 $1$,然后推式子
$$
\sum_{i = 1} ^ n \sum_{j = 1} ^ m [\gcd(i, j) = k].
$$
只有 $k$ 的倍数有用,缩放 $k$ 倍,得
$$
\sum_{i = 1} ^ {\frac n k} \sum_{j = 1} ^ {\frac m k} [\gcd(i, j) = 1].
$$
莫比乌斯反演,得
$$
\sum_{i = 1} ^ {\frac n k} \sum_{j = 1} ^ {\frac m k} \sum_{d\mid \gcd(i, j)} \mu(d).
$$
枚举约数 $d$,记 $c = \min(\frac n k, \frac m k)$,则
$$
\sum_{d = 1} ^ c \mu(d) \sum_{i = 1} ^ {\frac n k} [d\mid i] \sum_{j = 1} ^ {\frac m k} [d\mid j].
$$
由于 $1\sim x$ 当中 $y$ 的倍数有 $\frac x y$ 个,故原式化为
$$
\sum_{d = 1} ^ c \mu(d) \dfrac n {kd} \dfrac m {kd}.
$$
二维数论分块即可,时间复杂度 $\mathcal{O}(n + T\sqrt n)$。注意非必要不开 `long long`。[代码](https://uoj.ac/submission/663975)。
也可以不做二维差分,用四维数论分块替换四个二维数论分块,减小常数。[代码](https://uoj.ac/submission/823927)。
单组询问:[P3455 [POI2007] ZAP-Queries](https://www.luogu.com.cn/problem/P3455)。
#### [P1447 [NOI2010] 能量采集](https://www.luogu.com.cn/problem/P1447)
容易发现答案即 $2\sum_{i = 1} ^ n \sum_{j = 1} ^ m \gcd(i, j) - nm$,可以直接莫反硬推式子。
也可以对每个 $d$ 求出 $\gcd(i, j) = d$ 的对数,这是最开始的引入当中提到的对 $\gcd(i, j)$ 是 $d$ 的倍数的对数做倍数容斥,即做狄利克雷后缀和的差分
时间复杂度 $\mathcal{O}(n\log n)$。[代码](https://uoj.ac/submission/664130)。
如果用技巧 4:
$$
\sum_{i = 1} ^ n\sum_{j = 1} ^ m \gcd(i, j) = \sum_{i = 1} ^ n\sum_{j = 1} ^ m \sum_{d\mid \gcd(i, j)} \varphi(d) = \sum_{d = 1} ^ n \varphi(d) \frac n d \frac m d.
$$
这样就是线性了!
#### [P4318 完全平方数](https://www.luogu.com.cn/problem/P4318)
设 $f(n)$ 表示 $[1, n]$ 当中非完全平方数倍数的数的个数。二分答案,找到最小的 $r$ 使得 $f(r) \geq K$,则 $r$ 即为所求。
首先去掉 $2 ^ 2, 3 ^ 2, \cdots, p ^ 2$ 的倍数,但同时是其中两个数的倍数的数会被算两次,所以加上 $(p_1p_2) ^ 2$ 的倍数,依次类推。这是倍数容斥,系数为莫比乌斯函数。因此
$$
f(n) = \sum_{i} \mu(i) \frac n {i ^ 2}.
$$
$i$ 的上界为 $\sqrt n$,直接计算即可。
时间复杂度 $\mathcal{O}(\sqrt n \log n)$。[代码](https://uoj.ac/submission/663977)。
#### [CF990G GCD Counting](https://www.luogu.com.cn/problem/CF990G)
设 $c_i$ 表示简单路径上所有点都是 $i$ 的倍数的点对数量,设 $s_i$ 表示答案,则 $c_i = \sum_{i\mid d} s_d$,狄利克雷后缀和。于是 $s_i = \sum_{i\mid d} c_i \mu(\frac {d} i)$,狄利克雷后缀差分即可。
$c_i$ 容易直接算。为了避免每次建图,用并查集维护连通块。
时间复杂度 $\mathcal{O}(V\log V + n d(V)\alpha(n))$。[代码](https://codeforces.com/contest/990/submission/232936834)。
#### [SP5971 LCMSUM - LCM Sum](https://www.luogu.com.cn/problem/SP5971)
$$
\begin{aligned}
& \sum_{i = 1} ^ n \operatorname{lcm}(i, n) \\
= \; & n \sum_{i = 1} ^ n \frac i {\gcd(i, n)} \\
= \; & n \sum_{d\mid n} \sum_{i = 1} ^ n \frac i d [\gcd(i, n) = d] \\
= \; & n \sum_{d\mid n} \sum_{i = 1} ^ {\frac n d} i \left[i\perp \frac n d\right].
\end{aligned}
$$
设 $F(n)$ 表示 $n$ 以内所有与 $n$ 互质的数的和。当 $n \geq 2$ 时,因为若 $x\perp n$ 则 $n - x\perp n$,所以与 $n$ 互质的数成对出现且和为 $n$。也就是说,每个与 $n$ 互质的数对 $F(n)$ 的平均贡献是 $\frac n 2$。因此 $F(n) = \frac{n \varphi(n)} 2$。
当 $n = 1$ 时,$F(1)$ 显然为 $1$。
另一种推导 $F$ 的方式是莫比乌斯反演:
$$
\begin{aligned}
F(n) & = \sum_{i = 1} ^ n i[i\perp n] \\
& = \sum_{i = 1} ^ n i \sum_{d \mid \gcd(i, n)} \mu(d) \\
& = \sum_{d\mid n} \mu(d) \sum_{i = 1} ^ n i[d\mid i] \\
& = \sum_{d\mid n} \mu(d) d \frac{\frac n d (\frac n d + 1)}{2} \\
& = \frac n 2 \sum_{d\mid n} \mu(d) \left(\frac n d + 1\right) \\
& = \frac {n(\varphi(n) + \epsilon(n))} 2.
\end{aligned}
$$
最后一步是因为 $\mu * \mathrm{id} = \varphi$,$\mu * 1 = \epsilon$。答案即 $n\sum_{d\mid n} F(d)$,化简为 $\frac n 2 (1 + \sum_{d\mid n} d \varphi(d))$。
线性筛 $1 * (\mathrm{id} \times \varphi)$ 即可做到 $\mathcal{O}(T + n)$。[代码](https://uoj.ac/submission/663976)。
#### *[P2257 YY 的 GCD](https://www.luogu.com.cn/problem/P2257)
因为有多组询问,所以无法对每组 $n, m$ 都求出 $\gcd(i, j) = d$ 的对数。
$$
\begin{aligned}
& \sum_{i = 1} ^ n \sum_{j = 1} ^ m [\gcd(i, j)\in \mathbb P] \\
= \; & \sum_{p\in \mathbb P} \sum_{i = 1} ^ {\frac n p} \sum_{i = 1} ^ {\frac m p}[\gcd(i, j) = 1] \\
= \; & \sum_{p\in \mathbb P} \sum_{d = 1} ^ {\min(\frac n p, \frac m p)} \mu(d) \frac n {pd} \frac m{pd}.
\end{aligned}
$$
注意到分母上的 $pd
$ 与两个变量相关,较麻烦,故考虑设 $T = pd$,得
$$
\sum_{T = 1} ^ {\min(n, m)} \sum_{p\mid T\land p\in\mathbb P} ^ T \frac n T \frac m T \mu \left(\frac T p\right).
$$
这一步调整了计算顺序,使得可通过乘法分配律提出向下取整的式子。
另一种推导方式:对 $[\gcd(i, j) = p]$ 做倍数容斥,再对所有质数 $p$ 求和。贡献系数 $f$ 为所有容斥系数之和,即 $f(n) = \sum_{p\in \mathbb P} (\mu * \epsilon_p)(n)$,也就是 $f$ 等于将 $\mu$ 的下标扩大质数倍后求和。于是 $f(T) = \sum_{p \mid T\land p\in \mathbb P} \mu(\frac T p)$,与上式等价。
$f$ 可以类埃氏筛 $n\log\log n$ 求出,因为每个位置仅与其所有质因数有关。求出 $f$ 的前缀和,数论分块即可。时间复杂度 $\mathcal{O}(T\sqrt n + n \log\log n)$。
尽管 $f$ 不是积性函数,但 $f(T)$ 可以类似线性筛积性函数求出。
时间复杂度 $\mathcal{O}(T\sqrt n+n)$。[代码](https://uoj.ac/submission/663978)。
单组询问:[P2568 GCD](https://www.luogu.com.cn/problem/P2568)。
#### *[P1829 [国家集训队] Crash 的数字表格](https://www.luogu.com.cn/problem/P1829)
记 $c = \min(n, m)$。
根据 $\operatorname{lcm} = \frac {ij} {\gcd}$,枚举 $d = \gcd(i, j)$,得
$$
\begin{aligned}
& \sum_{d = 1} ^ c \sum_{i = 1} ^ n \sum_{j = 1} ^ m \frac {ij} d [\gcd(i, j) = d] \\
= \, & \sum\limits_{d = 1} ^ c d \sum\limits_{i = 1} ^ {\frac n d} \sum\limits_{j = 1} ^ {\frac m d} ij [i\perp j].
\end{aligned}
$$
莫比乌斯反演,得
$$
\begin{aligned}
& \sum_{d = 1} ^ c d \sum_{e = 1} ^ {\frac c d} \mu(e) \sum_{i = 1} ^ {\frac n d} \sum_{j = 1} ^ {\frac m d} ij [e\mid i \land e\mid j] \\
= \, & \sum_{d = 1} ^ c d \sum_{e = 1} ^ {\frac c d} \mu(e) e ^ 2 \sum_{i = 1} ^ {\frac n {de}} \sum_{j = 1} ^ {\frac m {de}} ij.
\end{aligned}
$$
后面两个 $\Sigma$ 容易计算,但难以融入化简。考虑设 $T = de$,$S(T) = \sum_{i = 1} ^ {\frac n T}\sum_{j = 1} ^ \frac m T ij$,交换枚举顺序,得
$$
\begin{aligned}
& \sum\limits_{T = 1} ^ c S(T) \sum\limits_{e \mid T} \mu(e) e ^ 2 \frac T e \\
= \, & \sum\limits_{T = 1} ^ c S(T) T \sum\limits_{e \mid T} \mu(e) e.
\end{aligned}
$$
至此已经可以狄利克雷前缀和。不过我们可以做得更好。
注意到 $\mu \cdot \mathrm{id}$ 是积性函数,所以 $f = 1 * (\mu \cdot \mathrm{id})$ 也是积性函数,可线性筛。则答案化简为 $\sum_{i = 1} ^ c S(i)f(i)i$,其中仅 $S$ 与 $n, m$ 有关。同时,注意到 $S$ 仅涉及 $n, m$ 整除值处的等差数列求和,因此求出 $f(i) i$ 的前缀和后,可数论分块 $\mathcal{O} (\sqrt c)$ 计算答案。
时间复杂度 $\mathcal{O}(c + T\sqrt c)$。[代码](https://uoj.ac/submission/663983)。
#### [AT5200 [AGC038C] LCMs](https://www.luogu.com.cn/problem/AT5200)
记 $S = \sum_{i = 1} ^ N \sum_{j = 1} ^ N \mathrm{lcm}(A_i, A_j)$,则答案为 $S$ 减去 $\sum_{i = 1} ^ N A_i$ 再除以 $2$。问题转化为求 $S$。
从枚举下标变成枚举值,设 $c_i$ 表示 $i$ 在 $\{A\}$ 当中的出现次数,即 $c_i = \sum_{j = 1} ^ N [A_j = i]$,则
$$
\begin{aligned}
S
& = \sum_{i = 1} ^ N \sum_{j = 1} ^ N \operatorname{lcm}(A_i, A_j) \\
& = \sum_{d = 1} ^ V \sum_{i = 1} ^ N \sum_{j = 1} ^ N \frac {A_iA_j} d [\gcd(A_i, A_j) = d] \\
& = \sum_{d = 1} ^ V \sum_{i = 1} ^ V \sum_{j = 1} ^ V \frac {ij c_i c_j} d [\gcd(i, j) = d] \\
& = \sum_{d = 1} ^ V d \sum_{i = 1} ^ {\frac V d} \sum_{j = 1} ^ {\frac V d} ij c_{id} c_{jd} [\gcd(i, j) = 1] \\
& = \sum_{d = 1} ^ V d \sum_{d' = 1} ^ {\frac V d} \mu(d') {d'} ^ 2 \sum_{i = 1} ^ {\frac V {dd'}} \sum_{j = 1} ^ {\frac V {dd'}} ij c_{idd'} c_{jdd'} \\
& = \sum_{T = 1} ^ V \sum_{d \mid T} \mu(d) d ^ 2 \frac T d \sum_{i = 1} ^ {\frac V T} \sum_{j = 1} ^ {\frac V T} ijc_{iT}c_{jT} \\
& = \sum_{T = 1} ^ V T f(T) g ^ 2(T).
\end{aligned}
$$
其中 $T = dd'$,$f(T) = \sum_{d\mid T} \mu(d) d$,$g(T) = \sum_{i = 1} ^ {\frac V T} ic_{iT}$。
$f$ 容易线性筛预处理,$g$ 可以枚举因数或狄利克雷后缀和。
时间复杂度 $\mathcal{O}(V\log V)$ 或 $\mathcal{O}(V\log\log V)$。[代码](https://atcoder.jp/contests/agc038/submissions/35024990)。
类似题目:[P3911 最小公倍数之和](https://www.luogu.com.cn/problem/P3911)。
#### [P6810 「MCOI-02」Convex Hull 凸包](https://www.luogu.com.cn/problem/P6810)
记 $c = \min(n, m)$。
$$
\begin{aligned}
\mathrm{answer} & = \sum_{d = 1} ^ c \tau(d) \sum_{i = 1} ^ {\frac n d} \sum_{j = 1} ^ {\frac m d} \tau(id)\tau(jd)[\gcd(i, j) = 1] \\
& = \sum_{d = 1} ^ c \tau(d) \sum_{d' = 1} ^ {\frac c d} \mu(d') \sum_{i = 1} ^ {\frac n {dd'}} \sum_{j = 1} ^ {\frac m {dd'}} \tau(idd')\tau(jdd').
\end{aligned}
$$
类似 AT5200 的套路,枚举 $T = dd'$,$\mathcal{O}(n\ln n)$ 分别预处理前面和后面,时间复杂度 $\mathcal{O}(n\ln n)$。
实际上有更简单的推法:系数 $\tau(\gcd(i, j))$ 启发我们将 $\tau(i)\tau(j)$ 摊在所有 $i, j$ 的公约数上,所以枚举公约数可得
$$
\begin{aligned}
\mathrm{answer} & = \sum_{i = 1} ^ n \sum_{j = 1} ^ m \tau(i)\tau(j) \sum_{d\mid i\land d\mid j} 1 \\
& = \sum_{d = 1} ^ c \sum_{i = 1} ^ {\frac n d} \sum_{j = 1} ^ {\frac m d} \tau(id)\tau(jd).
\end{aligned}
$$
直接预处理即可,时间复杂度 $\mathcal{O}(n\ln n)$。[代码](https://uoj.ac/submission/664859)。
两种做法均可使用狄利克雷后缀和做到 $\mathcal{O}(n\log\log n)$。
#### [P6156 简单题](https://www.luogu.com.cn/problem/P6156)
和前几题一样的套路。枚举 $\gcd$,再莫比乌斯反演,根据 $f(n) = \mu ^ 2(n)$ 得
$$
\sum_{d = 1} ^ n d ^ {k + 1} \mu ^ 2(d) \sum_{d' = 1} ^ {\frac n d} {d'} ^ k \mu(d') \sum_{i = 1} ^ {\frac n {dd'}}\sum_{j = 1} ^ {\frac n {dd'}} (i + j) ^ k.
$$
记 $T = dd'$,得
$$
\sum_{T = 1} ^ n T ^ k \sum_{d \mid T} d \mu ^ 2(d) \mu\left(\frac n d\right) \sum_{i = 1} ^ {\frac n T}\sum_{j = 1} ^ {\frac n T} (i + j) ^ k.
$$
线性筛预处理 $f = (d\times \mu ^ 2) * \mu$ 的前缀和,并预处理自然数幂和(这部分要 $\mathcal{O}(\pi(n)\log k)$,即 $\mathcal{O}(n \frac {\log k} {\log n})$,因为至少得对所有质数求 $k$ 次幂)求后面的 $\sum (i + j) ^ k$。数论分块求答案。
时间复杂度 $\mathcal{O}(n\frac {\log k}{\log n})$,代码见下一题。
#### [P6222 「P6156 简单题」加强版](https://www.luogu.com.cn/problem/P6222)
时间复杂度 $\mathcal{O}(n\frac {\log k}{\log n} + T\sqrt n)$。注意卡空间。[代码](https://uoj.ac/submission/664131)。
#### [P6825 「EZEC-4」求和](https://www.luogu.com.cn/problem/P6825)
直接莫反
$$
\begin{aligned}
& \sum_{d = 1} ^ n \sum_{i = 1} ^ {\frac n d} \sum_{j = 1} ^ {\frac n d}[i\perp j] d ^ {d(i + j)} \\
= \, & \sum_{d = 1} ^ n \sum_{k = 1} ^ {\frac n d} \mu(k) \sum_{i = 1} ^ {\frac n {dk}} \sum_{j = 1} ^ {\frac n {dk}} d ^ {kd(i + j)} \\
= \, & \sum_{d = 1} ^ n \sum_{k = 1} ^ {\frac n d} \mu(k) \left(\sum_{i = 1} ^ {\frac n {dk}} d ^ {kdi}\right) ^ 2.
\end{aligned}
$$
等比数列求和 & 快速幂,时间 $\mathcal{O}(n\log n\log p)$,常数较大。可以进一步优化,但比较平凡。
提供一个简单的小常数 2log 做法。
因为幂次很大,不同底数很难合并,所以考虑枚举底数即最大公约数 $d$。注意到指数是 $d$ 的倍数,所以底数-指数对只有 $\mathcal{O}(n\log n)$ 个。
这启发我们对于 $d$,枚举所有可能的倍数 $kd$,并求出有多少组对应的 $(id, jd)$ 满足 $1\leq id, jd\leq n$,$id + jd = kd$ 且 $i\perp j$。根据辗转相除法,$i\perp j$ 当且仅当 $i\perp (i + j)$,即 $i\perp k$。因此 $d ^ {kd}$ 的数量等于
$$
\sum_{i = l} ^ r [i\perp k] = \sum_{i = l} ^ r \sum_{d\mid i, k} \mu(d) = \sum_{d\mid k} \mu(d) \sum_{i = l} ^ r [d\mid i],
$$
其中 $l, r$ 是 $i$ 的上下界。枚举约数计算,则单个 $d$ 的时间复杂度为 $1\sim \frac n d$ 的约数个数和,即 $\mathcal{O}(\frac n d\log \frac n d)$。
总时间 $\sum_{d = 1} ^ n \frac {n} d\log \frac n d$,即 $\mathcal{O}(n\log ^ 2 n)$,但常数很小,而且很好写。[代码](https://uoj.ac/submission/824356)。
#### *[P3327 [SDOI2015] 约数个数和](https://www.luogu.com.cn/problem/P3327)
使用结论 3,套入莫反,得
$$
\sum_{d = 1} ^ {\min(n, m)} \mu(d) \sum\limits_{x = 1} ^ {\frac n d} \sum_{y = 1} ^ {\frac m d} \frac n {xd} \frac m {yd}.
$$
数论分块预处理 $g(n) = \sum_{i = 1} ^ n \frac n i$,则答案为 $\sum_{d = 1} ^ {\min(n, m)} \mu(d) g(\frac n d) g(\frac m d)$,数论分块即可。
时间复杂度 $\mathcal{O}((n + T)\sqrt n)$。[代码](https://uoj.ac/submission/664132)。
#### [CF1043F Make It One](https://www.luogu.com.cn/problem/CF1043F)
首先,若有解则答案不超过 $7$,因为一个数最多有 $6$ 个质因数,我们先选择任意数,再对它的每个质因数选择不含该质因数的数。
**算法 1**
设 $f_{i, j}$ 表示大小为 $i$ 且 $\gcd = j$ 的子集数量。莫比乌斯反演,设 $g_{i, j}$ 表示 $\gcd$ 为 $j$ 的倍数的子集数量,则 $g_{i, j} = c_j ^ i$,其中 $c_j$ 表示初始序列中 $j$ 的倍数,则 $f_{i, j} = \sum_{j\mid k} \mu(\frac k j) g_{i, k}$,即倍数容斥。
至此已经可以通过了,但取模不太好看。
**算法 2**
考虑在 $f_{i - 1}$ 的基础上添加一层 $f_1$,则 $f_i$ 等于 $f_{i - 1}$ 和 $f_1$ 做 $\gcd$ 卷积,即 $a_i b_j\to c_{\gcd(i, j)}$。这个可以直接倍数容斥。每做一次卷积就令 $f_{i, j} = [f_{i, j} > 0]$,即修改 $f$ 的定义为是否存在大小为 $i$ 且 $\gcd = j$ 的子集。这样值域就在平方范围内了,不需要取模。
两个算法本质相同,但是后者降低了值域范围。
视 $n, a_i$ 同级。$i$ 的数量级为最大本质不同质因数数量 $\mathcal{O}(\frac {\log n} {\log \log n})$,每次暴力倍数容斥 $\mathcal{O}(n\ln n)$,时间复杂度为 $\mathcal{O}(\frac {n\log ^ 2 n} {\log\log n})$。[代码](https://codeforces.com/contest/1043/submission/190068997)。
若容斥部分用狄利克雷前缀和实现则时间为 $\mathcal{O}(n\log n)$。进一步地,将算法一的枚举改成二分,算法二的枚举改成倍增,时间复杂度 $\mathcal{O}(n\log(\frac {\log n}{\log \log n}) \log\log n)$ 即 $\mathcal{O}(n\log ^ 2\log n)$。
#### [P3704 [SDOI2017] 数字表格](https://www.luogu.com.cn/problem/P3704)
记 $c = \min(n, m)$。
$$
\begin{aligned}
\mathrm{answer} & = \prod_{i = 1} ^ n \prod_{j = 1} ^ m f_{\gcd(i, j)} \\
& = \prod_{d = 1} ^ c f_d ^ {\sum_{i = 1} ^ n \sum_{j = 1} ^ m [\gcd(i, j) = d]} \\
& = \prod_{d = 1} ^ c f_d ^ {\sum_{d' = 1} ^ \frac c d \mu(d') \frac n {dd'} \frac m {dd'}} \\
& = \prod_{T = 1} ^ c \left(\prod_{d\mid T} f_d ^ {\mu(\frac n d)} \right) ^ {\frac n T \frac m T}.
\end{aligned}
$$
预处理 $f$ 及其逆元,预处理 $g(n) = \prod_{d\mid n} f_d ^ {\mu(\frac n d)}$。
对每组询问数论分块即可做到 $\mathcal{O}(n\log n + T\sqrt n\log n)$。[代码](https://uoj.ac/submission/664863)。
#### [P4152 [WC2014] 时空穿梭](https://www.luogu.com.cn/problem/P4152)
一条直线由两个点确定。枚举第一个点和最后一个点得到每个维度的差值 $x_{1\sim n}$,则中途(不含两端)经过的整点数量为 $\gcd(x_{1\sim n}) - 1$,方案数为 $\binom {d - 1} {c - 2}$。考虑先枚举 $x_{1\sim n}$ 再枚举两端的点,答案为
$$
\begin{aligned}
& \sum_{x_{1\sim n}} \binom {\gcd(x_{1\sim n}) - 1} {c - 2} \prod_{i = 1} ^ n (m_i - x_i). \\
= \; & \sum_{d = 1} ^ M \binom {d - 1} {c - 2} \sum_{x_{1\sim n}} [\gcd(x_{1\sim n}) = 1] \prod_{i = 1} ^ n (m_i - x_id) \\
= \; & \sum_{d = 1} ^ M \binom {d - 1} {c - 2} \sum_{d' = 1} ^ {M / d} \mu(d') \prod_{i = 1} ^ n \sum_{x_i = 1} ^ {m_i / dd'} (m_i - x_idd') \\
= \; & \sum_{X = 1} ^ M \prod_{i = 1} ^ n \sum_{x_i = 1} ^ {m_i / X} (m_i - x_iX) \sum_{d\mid X}\binom {d - 1} {c - 2} \mu\left(\frac X d\right). \\
\end{aligned}
$$
于是问题分成两部分:
$$
\begin{aligned}
f(X) & = \prod_{i = 1} ^ n \left(m_i k_i - Xk_i(k_i + 1) / 2\right),\\
g(X) & = \sum_{d\mid X} \binom {d - 1} {c - 2} \mu(X / d).
\end{aligned}
$$
其中 $k_i = \lfloor \frac {m_i} X\rfloor$。
时间复杂度 $\mathcal{O}(T(nm + m\log m))$,需要卡常。[代码](https://qoj.ac/submission/2085400)。
- 注意到 $c$ 比 $T$ 小,可以 $\mathcal{O}(cm\log m)$ 预处理 $g(c, X)$。
- 整数除法很慢,我们需要计算 $\mathcal{O}(nm)$ 次 $k$,可以用数论分块优化到 $\mathcal{O}(n ^ 2\sqrt m)$ 次。
瓶颈在 $Tnm$,怎么优化?数论分块固定了所有 $k_i$ 之后,$f(X)$ 是关于 $X$ 的 $n$ 次多项式。算出多项式,并预处理 $i ^ {0\sim n}$ 的前缀和。直接算是 $\mathcal{O}(n ^ 2)$,还要优化。在 $k_i$ 改变时除掉原线性式,再乘以新线性式。注意线性式等于零的情况,记录有多少个零即可。
时间 $\mathcal{O}(Tn ^ 2\sqrt m + cm\log m)$。
#### [P5518 [MtOI2019] 幽灵乐团 / 莫比乌斯反演基础练习题](https://www.luogu.com.cn/problem/P5518)
工作量极大的莫反练习题,有一定技术含量。
将 $\frac {\operatorname{lcm} (i, j)} {\gcd(i, k)}$ 写成 $\frac {i \cdot j} {\gcd(i, j) \gcd(i, k)}$。外层求积,可将问题拆成两部分:计算 $\prod i ^ {f(type)}$ 和 $\prod \gcd(i, j) ^ {f(type)}$,于是本题变成了无聊的六合一。
记 $F(n, m) = \sum_{i = 1} ^ n \sum_{j = 1} ^ m [i\perp j]$。
$$
{\color{red}\prod_{i, j, k} i} = \prod_{i} i ^ {BC}.
$$
预处理阶乘,复杂度 $\mathcal{O}(\log N)$。
$$
\begin{aligned}
{\color{red}\prod_{i, j, k} \gcd(i, j)} &= \prod_{d = 1} ^ {\min(A, B)} d ^ {F(\frac A d, \frac B d) C} \\
& = \prod_{d = 1} ^ {\min(A, B)} d ^ {\sum_{d' = 1} ^ {\frac {\min(A, B)} d} \mu(d') \frac {A} {dd'} \frac {B} {dd'} C} \\
& = \prod_{T = 1} ^ {\min(A, B)} \left(\prod_{d\mid T} d ^ {\mu(\frac T d)}\right) ^ {\frac A T\frac B T C}.
\end{aligned}
$$
预处理 $f_T = \prod_{d\mid T} d ^ {\mu(\frac T d)}$。对 $A, B$ 数论分块时需计算一段区间的 $f_T$ 的积,故预处理 $f_T$ 的前缀积和 $f_T$ 前缀积的逆元。时间复杂度 $\mathcal{O}(\sqrt N\log N)$。
$$
{\color{red}\prod_{i, j, k} i ^ {ijk}} = \prod_{i} (i ^ i) ^ {S(B)S(C)}.
$$
其中 $S(n) = \sum_{i = 1} ^ n i = \binom {n + 1} 2$。预处理 $i ^ i$ 的前缀积,复杂度 $\mathcal{O}(\log N)$。
$$
\begin{aligned}
{\color{red}\prod_{i, j, k} \gcd(i, j) ^ {ijk}} & = \prod_{d = 1} ^ {\min(A, B)} d ^ {d ^ 2{d'} ^ 2S(C) \sum_{d' = 1} ^ {\frac {\min(A, B)} {d}} \mu(d') S(\frac A {dd'}) S(\frac {B}{dd'})} \\
& = \prod_{T = 1} ^ {\min(A, B)} \left(\prod_{d \mid T} d ^ {T ^ 2 \mu(\frac T d)} \right) ^ {S(\frac A T) S(\frac B T) S(C)}.
\end{aligned}
$$
预处理 $f'_T = f_T ^ {T ^ 2}$,$f'$ 的前缀积和 $f'$ 前缀积的逆元。时间复杂度 $\mathcal{O}(\sqrt N\log N)$。
$$
{\color{red}\prod_{i = 1} ^ A \prod_{j = 1} ^ B \prod_{k = 1} ^ C i ^ {\gcd(i, j, k)}}.
$$
记 $L = \min(A, B, C)$,枚举最大公约数 $d$,得到
$$
\prod_{d = 1} ^ {L} \prod_{i = 1} ^ {\frac A d} (id) ^ {d \sum_{j = 1} ^ {\frac B d} \sum_{k = 1} ^ {\frac C d} [\gcd(i, j, k) = 1]}.
$$
莫比乌斯反演
$$
\begin{aligned}
& \prod_{d = 1} ^ {L} \prod_{i = 1} ^ {\frac A d} (id) ^ {d \sum_{j = 1} ^ {\frac B d} \sum_{k = 1} ^ {\frac C d} \sum_{d' \mid \gcd(i, j, k)} \mu(d')} \\
= \, &\prod_{d = 1} ^ {L} \prod_{d' = 1} ^ {\frac L d} \prod_{i = 1} ^ {\frac A {dd'}} (idd') ^ {d \sum_{j = 1} ^ {\frac B {dd'}} \sum_{k = 1} ^ {\frac C {dd'}} \mu(d')}.
\end{aligned}
$$
令 $T = dd'$,$D = \frac {A} T$,整理
$$
\begin{aligned}
& \prod_{T = 1} ^ {L} \prod_{d \mid T} \left(\prod_{i = 1} ^ {\frac A T} (iT) ^ {d\mu(\frac T d)}\right) ^ {\frac B {T} \frac C {T}} \\
= \, & \prod_{T = 1} ^ {L} \prod_{d \mid T} (D! \cdot T ^ D) ^ {d\mu(\frac T d)\frac B {T} \frac C {T}} \\
= \, & \prod_{T = 1} ^ {L} (D! \cdot T ^ D) ^ {\left(\sum_{d\mid T} d\mu(\frac T d)\right)\frac B {T} \frac C {T}} \\
= \, & \prod_{T = 1} ^ {L} \left(D! \cdot T ^ {D}\right) ^ { \varphi(T) \frac B {T} \frac C {T}}.
\end{aligned}
$$
数论分块时,对 $D!$ 需要求一段区间的 $\varphi(T)$ 之和,对 $T$ 需要求一段区间的 $T ^ {\varphi(T)}$ 之积,均可预处理。时间复杂度 $\mathcal{O}(\sqrt N\log N)$。
$$
{\color{red}\prod_{i = 1} ^ A \prod_{j = 1} ^ B \prod_{k = 1} ^ C \gcd(i, j) ^ {\gcd(i, j, k)}}.
$$
令 $L = \min(A, B)$,对 $\gcd(i, j)$ 莫比乌斯反演
$$
\prod_{d = 1} ^ {L} d ^ {\sum_{k = 1} ^ {C} \gcd(d, k) F(\frac A d, \frac B d)}.
$$
这里已经可以做了:容易推出 $\sum_{k = 1} ^ C \gcd(d, k) = \sum_{T\mid d} \varphi(T) \frac C T$(结论 4),而所有 $F(\frac A d, \frac B d)$ 可以数论分块套数论分块做到 $\mathcal{O}(N ^ {\frac 3 4})$,于是复杂度为 $\mathcal{O}(N\log N)$,需要大力卡常。
将结论套入:
$$
\prod_{T = 1} ^ L \left(\prod_{T'\mid T} T ^ {\varphi(T') \frac C {T'}}\right) ^ {F\left(\frac {A} {T}, \frac {B} {T}\right)}.
$$
设新的 $T$ 等于原来的 $\frac T {T'}$,则
$$
\prod_{T' = 1} ^ L \prod_{T = 1} ^ {\frac L {T'}} (TT') ^ {\varphi(T') \frac C {T'} F\left(\frac {A} {TT'}, \frac {B} {TT'}\right)}.
$$
拆成 $T$ 和 $T'$ 两部分:
$$
\prod_{T' = 1} ^ L \left(\prod_{T = 1} ^ {\frac L {T'}} T ^ {F\left(\frac {A} {TT'}, \frac {B} {TT'}\right)}\right) ^ {\varphi(T') \frac C {T'}},
$$
和
$$
\prod_{T' = 1} ^ L \left( {T'} ^ {\varphi(T') \frac C {T'}}\right) ^ {\sum_{T = 1} ^ {\frac L {T'}}F\left(\frac {A} {TT'}, \frac {B} {TT'}\right)}.
$$
注意到 $\sum_{i = 1} ^ {\min(A, B)} F(\frac A i, \frac B i) = AB$,因为每一对 $A, B$ 会在 $i = \gcd(A, B)$ 时计入答案,于是后面的部分为
$$
\prod_{T' = 1} ^ L {T'} ^ {\varphi(T') \frac C {T'}\frac {A} {T'} \frac {B} {T'}}.
$$
类似上一部分做,复杂度 $\mathcal{O}(\sqrt N\log N)$。
再把前面这部分写下来。
$$
\prod_{T' = 1} ^ L \left(\prod_{T = 1} ^ {\frac L {T'}} T ^ {F\left(\frac {A} {TT'}, \frac {B} {TT'}\right)}\right) ^ {\varphi(T') \frac C {T'}}.
$$
首先在外层对 $T'$ 做关于 $A, B, C$ 的三维数论分块,此时内层的
$$
\prod_{T = 1} ^ {\frac L {T'}} T ^ {F\left(\frac {A} {TT'}, \frac {B} {TT'}\right)}
$$
为定值。如果能快速计算,则它的 $\frac {C} {T'}\sum \varphi(T')$ 次幂就是当前 $T'$ 区间的答案。
$F$ 可以数论分块根号求(P2522),于是对 $T$ 数论分块之后就是数论分块套数论分块套数论分块,时间 $\mathcal{O}(N ^ {\frac 7 8})$,不优美。
注意到 $F(\frac A {TT'}, \frac B {TT'})$ 在整个过程中只有 $\mathcal{O}(\sqrt L)$ 种不同的取值,可以先数论分块套数论分块预处理,即可 $\mathcal{O}(1)$ 求出 $F(\frac {A} {TT'}, \frac {B} {BB'})$。
对 $T$ 数论分块,时间为数论分块套数论分块结合内层快速幂的 $\mathcal{O}(N ^ {\frac 3 4}\log N)$。
综上,预处理复杂度为 $\mathcal{O}(N\log N)$,单次询问的复杂度为 $\mathcal{O}(N ^ {\frac 3 4}\log N)$。可能可以进行更多预处理以达到更优秀的复杂度。
本题的启发:**写成 $\sum_{T = 1} ^ n \sum _{d\mid T}$ 方便预处理,写成 $\sum_{T = 1} ^ n \sum_{d = 1} ^ {\frac n T}$ 方便直接求**。**不要急着把一大坨式子展开,说不定可以预处理**。
#### *[P5572 [CmdOI2019] 简单的数论题](https://www.luogu.com.cn/problem/P5572)
$$
\begin{aligned}
& \sum_{i = 1} ^ n \sum_{j = 1} ^ m \varphi\left( \frac {i j} {\gcd ^ 2(i, j)}\right) \\
= \; & \sum_{i = 1} ^ n \sum_{j = 1} ^ m \varphi\left( \frac {i} {\gcd(i, j)}\right) \varphi\left( \dfrac {j} {\gcd(i, j)}\right) \\
= \; & \sum_{d = 1} ^ m \sum_{i = 1} ^ {\frac n d} \sum_{j = 1} ^ {\frac m d} \varphi(i) \varphi(j) [i\perp j] \\
= \; & \sum_{d = 1} ^ m \sum_{d' = 1} ^ {\frac m d} \mu(d') \sum_{i = 1} ^ {\frac n {dd'}} \sum_{j = 1} ^ {\frac m {dd'}} \varphi(id') \varphi(jd') \\
= \; & \sum_{T = 1} ^ m \sum_{d\mid T} \mu(d) \left(\sum_{i = 1} ^ {\frac n T} \varphi(id) \right) \left(\sum_{j = 1} ^ {\frac m T} \varphi(jd) \right).
\end{aligned}
$$
第二步用到了 $\varphi$ 的积性。
求出不大于某值的所有 $d$ 的倍数的 $\varphi$ 之和的形式出现多次,所以首先 $\mathcal{O}(n\ln n)$ 预处理 $f(d, s)$ 表示 $\sum_{i = 1} ^ s \varphi(id)$。
计算单个 $T$ 的复杂度为 $d(T)$,且当 $T$ 大的时候,$\frac n T$ 和 $\frac m T$ 较小,所以我们考虑根号分治。
对于 $T\leq \sqrt n$,直接暴力枚举 $T, d$ 计算 $\sum_{T = 1} ^ m \sum_{d\mid T} \mu(d) f(d, \frac n T) f(d, \frac m T)$。单组询问 $\mathcal{O}(\sqrt n \log n)$。
对于 $T \geq \sqrt n$,$\frac n T\leq \sqrt n$,预处理 $g(i, j, s)$ 表示 $\sum_{T = 1} ^ s \sum_{d\mid T} \mu(d)f(d, i) f(d, j)$,则一段使得整除值 $\frac n T$ 和 $\frac m T$ 相同的 $T\in [l, r]$ 的贡献可直接表示为 $g(\frac n T, \frac m T, r) - g(\frac n T, \frac m T, l - 1)$。注意到 $i \geq j$ 且 $s$ 的上界为 $\frac n i$(要使 $\frac n T = i$,则 $T$ 不会超过 $n$ 的最大值除以 $i$),所以对于每个 $i$ 的 $(j, s)$ 对数为 $i\times \frac n i = n$。对每个 $i\leq \sqrt n$ 预处理 $g(i, j, s)$,空间复杂度 $\mathcal{O}(n\sqrt n)$,时间复杂度 $\mathcal{O}(n\sqrt n\log n)$ 或 $\mathcal{O}(n\sqrt n \log\log n)$。每组询问内求答案则是直接数论分块。
综上,时间复杂度 $\mathcal{O}((n + T)\sqrt n\log n)$。[代码](https://uoj.ac/submission/663989)。
#### [P4619 [SDOI2018] 旧试题](https://www.luogu.com.cn/problem/P4619)
类似结论 4 的思路,
$$
d(ijk) = \sum_{x \mid i} \sum_{y\mid j} \sum_{z\mid k} [x\perp y][x\perp z][y\perp z].
$$
因此答案可写为
$$
\sum_{i = 1} ^ A \sum_{j = 1} ^ B \sum_{k = 1} ^ C[i\perp j][i, j\perp k] \frac A i \frac B j\frac C k.
$$
形式比较复杂,先做一次关于 $i, j$ 的莫反试试水。
$$
\sum_{d = 1} ^ {\min(A, B)} \mu(d) \sum_{i = 1} ^ {\frac A d} \sum_{j = 1} ^ {\frac B d} \sum_{k = 1} ^ C [i, j, d \perp k] \frac A {id} \frac B {jd} \frac C k.
$$
看起来相当不可做。不要忘记我们做莫反的核心目的是将 $i, j$ 独立开来,同时注意到所有互质的条件均和 $k$ 有关,所以先枚举 $k$,得到
$$
\sum_{k = 1} ^ {C} \sum_{d = 1} ^ {\min(A, B)} [d\perp k]\mu(d) \left(\sum_{i = 1} ^ {\frac A d} [i\perp k]\frac A {id}\right) \left(\sum_{j = 1} ^ {\frac B d} [j\perp k] \frac B {jd} \right).
$$
观察 $i, j$ 共同具有的形式,设
$$
f(k, n) = \sum_{i = 1} ^ n [i\perp k] \frac n i,
$$
则
$$
\sum_{k = 1} ^ C \sum_{d = 1} ^ {\min(A, B)} [d\perp k] \mu(d) f(k, A / d ) f(k, B / d).
$$
注意到 $f$ 的第二维只能是 $A$ 或 $B$ 的整除值,所以共有 $\mathcal{O}(V \sqrt V)$ 对 $(k, n)$ 二元组,且二维数论分块后问题转化为求
$$
\sum_{d = l} ^ r [d\perp k] \mu(d).
$$
设
$$
g(k, n) = \sum_{d = 1} ^ n [d\perp k] \mu(d),
$$
则 $n$ 是所有使得整除值相等的区间右端点,所以 $n$ 本身也是 $A$ 或 $B$ 的整除值。
可以直接莫反求 $f, g$,需要预处理以加速计算。例如
$$
f(k, n) = \sum_{d\mid k} \mu(d) \sum_{i = 1} ^ {\frac n d} \frac n {id}.
$$
需要预处理 $h(n) = \sum_{i = 1} ^ n \frac n i$。时间 $\mathcal{O}(V\sqrt V\log V)$,[代码](https://qoj.ac/submission/2076354)。洛谷评测机较慢,无法通过。
换一种思路,考虑递推(来自 [Vocalise 的题解](https://www.luogu.com.cn/article/86uf1xh3))。
$$
f(k, n) = \sum_{i = 1} ^ n [i\perp k] \frac n i.
$$
$k = 1$ 时显然 $f(1, n) = h(n)$。否则,我们将 $k$ 除掉任意质因数 $p$,考虑在 $f(\frac k p, n)$ 的基础上还要去掉哪些 $i$ 的贡献:$i\perp \frac k p$ 但 $i\not\perp k$。如果 $\frac k p$ 本身就是 $p$ 的倍数,显然不变。否则 $i$ 肯定得是 $p$ 的倍数,且 $i\perp \frac k p$ 即 $\frac i p \perp \frac k p$(因为 $\frac k p$ 不含 $p$,可以放心地除掉 $i$ 里面的 $p$),所以
$$
\begin{aligned}
f(k, n) & = f(k/ p, n) - [p\nmid k / p]\sum_{i = 1} ^ {\frac n p} [i\perp k / p] \frac n {ip} \\
& = f(k / p, n) - [p\nmid k / p] f(k / p, n / p).
\end{aligned}
$$
类似地,
$$
\begin{aligned}
g(k, n) & = g(k / p, n) - [p\nmid k / p] \sum_{i = 1} ^ {\frac n p} [i\perp k / p] \mu(ip) \\
& = g(k / p, n) - [p\nmid k / p] \sum_{i = 1} ^ {\frac n p} [i\perp k / p] \mu(i)\mu(p)[i\perp p] \\
& = g(k / p, n) + [p\nmid k / p] \sum_{i = 1} ^ {\frac n p} [i\perp k / p\land i\perp p] \mu(i) \\
& = g(k / p, n) + [p\nmid k / p] g(k, n / p).
\end{aligned}
$$
空间是 $\mathcal{O}(V\sqrt V)$,具体分析一下大约是 $3V\sqrt V$($1\sim \sqrt V$,$a, b$ 的大于 $\sqrt V$ 的整除值),还要开 $f, g$ 两个数组,不够用。
注意到递推时 $k$ 这个维度仅和 $k / p$ 有关(来自 [LHF 的题解](https://www.luogu.com.cn/article/a49gwvdz)),因此考虑按添加质因数的方式枚举 $k$,就可以用 $\mathcal{O}(\omega(V))$ 个线性数组存下信息。
时间复杂度 $\mathcal{O}(V\sqrt V)$。[代码](https://qoj.ac/submission/2076359)。