int l = 1, r = 100;
int x; // 小 A 想的数
while (true) {
int mid = (l + r) / 2;
if (mid == x) { // 此次猜测为答案
cout << mid;
exit(0); // 结束程序
}
if (mid < x) l = mid + 1;
else r = mid - 1;
}
如果你觉得上面的代码太菜了:
int x; // 小 A 想的数
cout << x;
开挂行为切勿模仿。
1.2 整数的二分查找
:::info[二分查找/靠左]{open}
给出 n 个单调不减的非负整数 a_1, \cdots, a_n,进行 m 次询问,每次询问一个非负整数 x 在 a 中第一次出现的位置(下标),若未出现过输出 -1。
:::
分析题目,我们确定答案的方式不能再是 $mid = x$ 了,因为我们不能确定 $mid$ 是不是 $x$ 第一次出现在 $a$ 中的位置。
于是考虑逐步缩小区间,直到 $l = r$,此时 $l, r$ 就是想要得到的答案。这也是二分最通用的写法。
对于我们找到的 $mid$,该如何缩小区间?

如图,如果我们发现 $a_{mid} < x$,那么可以直接缩小区间到 $[mid + 1, r]$,使得我们想要的答案(红的区间的最左边端点)依然在区间内。

如图,当 $a_{mid} = x$,由于我们需要查找红色区间最左侧位置,所以需要将右端点左移。那么我们要使 $r$ 变为 $mid$ 还是 $mid - 1$ 呢?由于当前 $mid$ 可能是红色区域最左端,所以使 $r = mid - 1$ 可能会让答案被排在区间外,所以需要使 $r = mid$。

如图,当 $a_{mid} > x$,直接使 $r = mid - 1$ 是没有问题的。我们在二分时习惯于分为两种情况讨论,一般会使 $mid = r$,与 $a_{mid} = x$ 时一样。这样写没有问题,并且几乎不会慢多少,并且能提高代码的可读性。
最后,别忘了如果二分出来的 $l$(或者 $r$)不满足 $a_l = x$,代表无解,输出 `-1`。
根据上述思路,可以打出以下代码:
```cpp
#include <iostream>
using namespace std;
constexpr int N = 1e6 + 5;
int n, a[N], m, x;
int main () {
cin >> n >> m;
for (int i = 1; i <= n; ++ i) cin >> a[i];
while (m --) {
cin >> x;
int l = 1, r = n;
while (l < r) {
int mid = l + r >> 1;
if (a[mid] < x) l = mid + 1;
else r = mid;
}
cout << (a[l] == x ? l : -1) << ' ';
}
return 0;
}
```
:::info[[二分查找/靠右](http://bbcoj.cn/training/51/problem/BA302)]{open}
给出 $n$ 个单调不减的非负整数 $a_1, \cdots, a_n$,进行 $1$ 次询问一个非负整数 $x$ 在 $a$ 中最后出现的位置(下标),若未出现过输出 `-1`。
$1\leqslant n\leqslant 10^6, 1\leqslant m \leqslant 10^5, 1 \leqslant a_i, x \leqslant 10^9$。
:::
按照刚才靠左查找的思路,我们可以打出以下代码(核心部分):
```cpp
int mid = l + r >> 1;
if (a[mid] <= x) l = mid;
else r = mid - 1;
```
欸?为什么代码 **TLE** 了?
运行样例,输出每次二分后的 $l, r$,发现一直卡在了 $[4, 5]$ 死循环,这是为什么?
答案应该为 $5$,但是我们每次找到的 $mid$ 实际上为 $\dfrac{l + r}{2}$ 向下取整为 $4$,然后使 $l = mid$,区间无变化!
解决方法很简单,由于更新 $l$ 时不会让 $l = mid + 1$,向右查找时应该让我们的 $mid$ 向上取整,避免死循环。同样的,向左查找时我们应使 $mid$ 向下取整,只是由于 int 类型整数除法自动向下取整的特性帮我们避免了这一错误,实际上我们考虑的是不周全的。
更正后,能写出如下正确代码:
```cpp
#include <iostream>
using namespace std;
constexpr int N = 1e6 + 5;
int n, a[N], x;
int main () {
cin >> n;
for (int i = 1; i <= n; ++ i) cin >> a[i];
cin >> x;
int l = 1, r = n;
while (l < r) {
int mid = l + r + 1 >> 1;
if (a[mid] <= x) l = mid;
else r = mid - 1;
}
cout << (a[l] == x ? l : -1)
return 0;
}
```
向上还是向下取整以及 $l$ 和 $r$ 取到 $mid$ 时要不要加减 $1$ 就是二分中很细节和重要的部分。正是因为这些地方很容易考虑出错,所以有一句话这么说:
> 只有 $10\%$ 的程序员能写对二分。
做题时一定要考虑好这些细节!
#### 1.3 小数的二分查找
:::info[[数的三次方根](http://bbcoj.cn/training/51/problem/BA303)]{open}
给定一个浮点数 $n$,求 $n$ 的三次方根,保留 $6$ 位小数。
$0 \leqslant n \leqslant 10^4
:::
不难发现,对于 a\geqslant0 与 a^3,a^3 随 a 增大而增大。那我们设 f(x) = x^3,则 f(x)具有单调性。我们便可以二分查找答案 x 使得 f(x) = n。
注意题目中的要求精度为 10^{-6},那么我们对二分时的要求精度再小 10^{-2} 是最稳妥的,也就是 10^{-8}。那我们直接按照刚才整数域上的二分方法来二分即可,停止条件为 r - l \leqslant 10^{-8}。
可以写出以下代码:
#include <iostream>
#include <iomanip>
using namespace std;
double n;
constexpr double eps = 1e-8;
int main () {
cin >> n;
double l = 1, r = 100;
while (r - l > eps) {
double mid = (l + r) / 2;
if (mid * mid * mid < n) l = mid;
else r = mid;
}
cout << fixed << setprecision(6) << l;
return 0;
}
:::info[木材加工]{open}
伐木场有 n 根原木,每根的长度分别为 a_i,现在想要锯成 k 段长度均为 l 的木材,请最大化 l。
:::
首先可以想到暴力做法,从小到大枚举 $l$,直到发现无法凑出 $k$ 段木材,输出。这样的时间复杂度最差是 $\mathcal O(n^2k)$ 的。
**理性证明:**
我们可以发现,如果需要的木材长度为 $l$,那么可以拼凑出的木材段数为 $d_l = \sum_{i=1}^n \lfloor\frac{a_i}{l}\rfloor$,显然 $d_i$ 单调不升。那么对于最终的答案 $l$,$\forall ~l' < l$ 一定是满足要求的,而 $\forall ~l' > l$ 是不满足要求的。所以我们可以确定答案区间后每次找到当前答案区间 $[l, r]$ 的中间位置 $mid$,判断在木材长度为 $mid$ 的要求下是否能得到 $k$ 段木材,如果满足,把下限提升到 $mid$;如果不满足,把上限降低到 $mid - 1$。相当于一个二分靠右查找板子了。
**感性理解:**
如果我们要求的木材长度长,得到的数量就会少。如果我们要求的木材长度短,那么得到的数量就会多。那么一定会有一个临界点的木材长度 $l$,使得我们要求在它或它以下的时候能得到至少 $k$ 段木材,而要求比它高时得不到。这个 $l$ 就是我们要求的答案。相当于合法的区间就是 $[1, l]$,进行一个二分靠右查找。而判断 $mid$ 的方式也不再是二分查找中的 $a_{mid}$ 和 $x$ 的大小关系,而变成了 $\mathcal O(n)$ 地判断能得到多少木材,再与 $k$ 比较。
二分答案是什么?这个例题中我们所二分的 $l$,就是这个问题的答案,也就是二分答案了。而二分中的判断变为了判断当前的答案 $mid$ 的**可行性**。我们也能发现,二分答案本质上也是二分查找,区别在于判断方式。二分查找就是一种最简单的二分答案,判断方式比较简单,可以直接比较大小而已。而我们就能从二分查找逐渐理解二分的本质。
所以我们总结出二分答案的本质,就是**把找到最优答案改变为多次($\log n$ 次)判断一个答案的可行性**。
那是不是所有问题都能二分呢?
并不是。这道题有一个特殊的性质,就是对于木材长度对应的木材数量具有单调性,也就是二分查找中需要满足的数组的单调性。这样我们才能二分。
总结二分答案:
- 需要使答案满足单调性才能使用。
- 二分答案,判断可行性以缩小答案区间。
- 设计出检查答案可行性函数在 $\log n$ 次询问下不超时。
那么,这道题的代码也就很好写了:
```cpp
#include <iostream>
using namespace std;
using ll = long long;
constexpr int N = 1e5 + 5;
int n, k;
ll l[N], sum;
inline bool check (ll x) {
ll cnt = 0;
for (int i = 1; i <= n; ++ i) cnt += l[i] / x;
return cnt >= k;
}
int main () {
cin >> n >> k;
for (int i = 1; i <= n; ++ i) {
cin >> l[i];
sum += l[i];
}
ll l = 0, r = sum;
while (l < r) {
ll mid = l + r + 1 >> 1;
if (check(mid)) l = mid;
else r = mid - 1;
}
cout << l;
return 0;
}
```
再来一道基础例题巩固一下吧!
:::info[[数列分段 Section II](http://bbcoj.cn/training/53/problem/BA407)]{open}
有一个长度为 $n$ 的非负整数数列 $a_1, \cdots, a_n$,现在要求把数列划分为不超过 $m$ 段,使得每段的和的最大值最小。求这个最小的最大值 $k$。
$1\leqslant m\leqslant n\leqslant 10^5, 0\leqslant a_i\leqslant 10^8$。
保证答案不超过 $10^9$。
:::
还是根据二分答案的思路,我们应该先判断单调性。对于一个已经确定的 $k$,我们需要分段使得每一段的和不超过当前的 $k$。那么 $k$ 越小,分的段就会越多,也就越容易超过 $m$ 段的限制。那么思路就答大体已经出来了,对于答案 $k$,$\geqslant k$ 的部分分出来的块数是不多于 $m$ 的,所以判断可行性时,如果可行,$r = mid$;如果不可行,$l = mid + 1$,属于一个二分靠左查找。
还有一个细节,因为一个块至少要有一个数,所以二分初始下界应该设置为 $\max_{i=1}^{n}a_i$,否则需要在 check 函数里特判,比较麻烦。
```cpp
#include <iostream>
#include <algorithm>
using namespace std;
constexpr int N = 1e5 + 5;
int n, a[N], m, maxa;
inline bool check (int k) {
int cnt = 1, now = 0;
for (int i = 1; i <= n; ++ i) {
if (now + a[i] > k) now = 0, cnt ++;
now += a[i];
}
return cnt <= m;
}
int main () {
cin >> n >> m;
for (int i = 1; i <= n; ++ i) {
cin >> a[i];
maxa = max(maxa, a[i]);
}
int l = maxa, r = 1e9;
while (l < r) {
int mid = l + r >> 1;
if (check(mid)) r = mid;
else l = mid + 1;
}
cout << l;
return 0;
}
```
完成[习题](http://bbcoj.cn/training/53)以巩固对二分答案的掌握。
#### 2.2 进阶例题
阅读此部分前请确保自己已经学习了普及组考纲内的算法和小部分提高组算法喵。
这部分会涉及二分与其它算法的结合运用。
:::info[[[NOIP 2011 提高组] 聪明的质监员](https://www.luogu.com.cn/problem/P1314)]{open}
小 T 是一名质量监督员,最近负责检验一批矿产的质量。这批矿产共有 $n$ 个矿石,从 $1$ 到 $n$ 逐一编号,每个矿石都有自己的重量 $w_i$ 以及价值 $v_i$。检验矿产的流程是:
1. 给定 $m$ 个区间 $[l_i,r_i]$;
2. 选出一个参数 $W$;
3. 对于一个区间 $[l_i,r_i]$,计算矿石在这个区间上的检验值 $y_i$:
$$y_i=\sum\limits_{j=l_i}^{r_i}[w_j \ge W] \times \sum\limits_{j=l_i}^{r_i}[w_j \ge W]v_j$$
其中 $j$ 为矿石编号,$[p]$ 是指示函数,若条件 $p$ 为真返回 $1$,否则返回 $0$。
这批矿产的检验结果 $y$ 为各个区间的检验值之和。即:$\sum\limits_{i=1}^m y_i$。
若这批矿产的检验结果与所给标准值 $s$ 相差太多,就需要再去检验另一批矿产。小 T 不想费时间去检验另一批矿产,所以他想通过调整参数 $W$ 的值,让检验结果尽可能的靠近标准值 $s$,即使得 $|s-y|$ 最小。请你帮忙求出这个最小值。
$1 \leqslant n,m\leqslant2\times10^5$,$0 < w_i,v_i\leqslant10^6$,$0 < s\leqslant10^{12}$,$1 \leqslant l_i \leqslant r_i \leqslant n$。
:::
:::success[思路 & 代码]{open}
对于答案 $y$,显然随 $W$ 增加而单调不增。所以我们可以二分 $W$,判断得到的 $y$ 与 $s$ 的大小关系,再进行调整,中间记录 $y$ 和 $s$ 的差维护答案。
那么如何能 $\mathcal O(n)$ 地实现 check 函数?可以实现两个前缀和数组 $pre1, pre2$,分别表示:
$$pre1_i=\displaystyle\sum_{j=1}^{i}[w_j > W],~pre2_i=\displaystyle\sum_{j=1}^{i}[w_j > W]v_j$$
那么再对于每个询问,可以 $\mathcal O(1)$ 地查询。得到:
$$y=\displaystyle\sum_{i=1}^{m}[(pre1_r - pre1_{l - 1})\times(pre2_r - pre2_{l - 1})]$$
总时间复杂度 $\mathcal O(\log(\max_{i=1}^{n}w_j)\times(n + m))$。
```cpp
#include <iostream>
#include <algorithm>
#include <cmath>
using namespace std;
using ll = long long;
constexpr int N = 2e5 + 5;
int n, m, w[N], v[N], L[N], R[N];
ll s;
int mxw;
ll fnl = 1e18;
ll pre1[N], pre2[N];
inline bool check (int W) {
for (int i = 1; i <= n; ++ i) {
if (w[i] >= W) pre1[i] = pre1[i - 1] + 1, pre2[i] = pre2[i - 1] + v[i];
else pre1[i] = pre1[i - 1], pre2[i] = pre2[i - 1];
}
ll y = 0;
for (int i = 1; i <= m; ++ i) {
y += (pre1[R[i]] - pre1[L[i] - 1]) * (pre2[R[i]] - pre2[L[i] - 1]);
}
fnl = min(fnl, abs(s - y));
return y > s;
}
int main () {
cin >> n >> m >> s;
for (int i = 1; i <= n; ++ i) cin >> w[i] >> v[i], mxw = max(mxw, w[i]);
for (int i = 1; i <= m; ++ i) cin >> L[i] >> R[i];
int l = 0, r = mxw;
while (l <= r) {
int mid = l + r >> 1;
if (check(mid)) l = mid + 1;
else r = mid - 1;
}
cout << fnl;
return 0;
}
```
:::
:::info[[山](https://www.luogu.com.cn/problem/P1663)]{open}
给出一座山,如图。
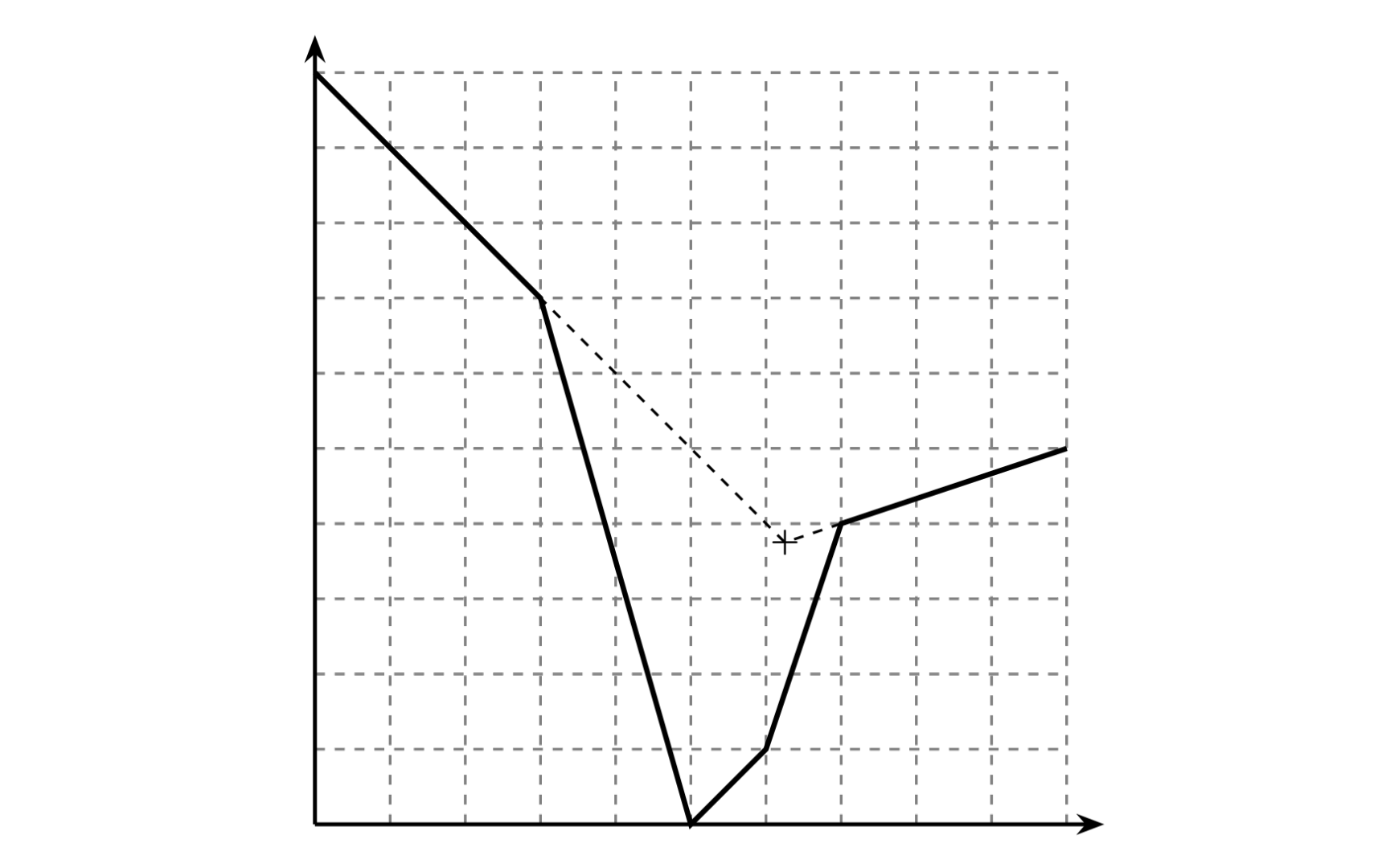
现在要在山上的某个部位装一盏灯,使得这座山的任何一个部位都能够被看到。
给出最小的 $y$ 坐标,如图的 `+` 号处就是 $y$ 坐标最小的安装灯的地方。
输入第一行一个数 $N$,表示这座山由 $N$ 个点构成;
接下来 $N$ 行从左到右给出了这座山的构造情况,每行两个数 $X_i, Y_i$,表示一个折点,保证 $X_i > X_{i-1}$。
:::
:::success[思路 & 代码]{open}
首先把 $n$ 个点转换为 $n - 1$ 条直线 $y = k_ix + b_i
显然可以二分 y 判断可行性。答案点 (x, y) 应当使 \forall i\in[1, n),y \geqslant k_ix + b_i。所以对于 k_i \not= 0 的直线,可以把对于确定的 y 的横坐标左右范围缩小到 \frac{y - b}{k} 左右,那么可以先将 k_i = 0 的直线中最大的 b 找出设为二分下界,再在每次判断 mid 可行性时讨论每一条直线,将 x 的可行区间逐步缩小,最后如果还存在可行的 x,则具有可行性。
时间复杂度 \mathcal O(\log(\frac{Y}{eps})n)。
#include <iostream>
#include <iomanip>
#include <algorithm>
#define double long double
using namespace std;
using PII = pair <double, double>;
constexpr int N = 5e3 + 5;
constexpr double eps = 1e-5;
int n;
PII node[N];
struct StraightLine {
double k, b;
} sl[N];
inline void getf (int id, PII a, PII b) {
sl[id].k = (a.second - b.second) / (a.first - b.first);
sl[id].b = a.second - sl[id].k * a.first;
}
inline bool check (double y) {
double liml = 0, limr = 1e5;
for (int i = 1; i <= n; ++ i) {
double gtx = (y - sl[i].b) / sl[i].k;
if (sl[i].k == 0) continue;
if (sl[i].k > 0) {
limr = min(limr, gtx);
} else {
liml = max(liml, gtx);
}
if (liml > limr) return false;
}
return true;
}
int main () {
cin >> n;
for (int i = 1; i <= n; ++ i) {
cin >> node[i].first >> node[i].second;
if (i != 1) getf(i - 1, node[i - 1], node[i]);
}
n --;
double l = 0, r = 1e6, ans = 1e6;
for (int i = 1; i <= n; ++ i) {
if (sl[i].k == 0) l = max(l, sl[i].b);
}
while (r - l > eps) {
double mid = (l + r) / 2;
if (check(mid)) r = mid - eps, ans = mid;
else l = mid + eps;
}
cout << fixed << setprecision(6) << ans;
return 0;
}
:::
:::info[天路]{open}
小 X 的梦中,他在西藏开了一家大型旅游公司,现在,他要为西藏的各个景点设计一组铁路线。但是,小 X 发现,来旅游的游客都很挑剔,他们乘火车在各个景点间游览,景点的趣味当然是不用说啦,关键是路上。试想,若是乘火车一圈转悠,却发现回到了游玩过的某个景点,花了一大堆钱却在路上看不到好的风景,那是有多么的恼火啊。
所以,小 X 为所有的路径定义了两个值,V_i 和 P_i,分别表示火车线路的风景趣味度和乘坐一次的价格。现在小 X 想知道,乘客从任意一个景点开始坐火车走过的一条回路上所有的 V 之和与 P 之和的比值的最大值。以便为顾客们推荐一条环绕旅游路线(路线不一定包含所有的景点,但是不可以存在重复的火车路线)。
于是,小 X 梦醒之后找到了你……
输入第一行两个正整数 N,M,表示有 N 个景点,M 条火车路线,火车路线是单向的。
以下 M 行,每行 4 个正整数,分别表示一条路线的起点,终点,V 值和 P 值。
注意,两个顶点间可能有多条轨道,但一次只能走其中的一条。
:::
:::success[思路 & 代码]{open}
显然对于答案 $ans$,以下都具有可行性,以上都不具有可行性,故可以二分求解。
根据题意,有:
$$\dfrac{\sum V_i}{\sum P_i}\leqslant ans$$
则有:
$$\sum V_i\leqslant \sum P_i\times ans$$
则有:
$$\sum P_i\times ans - \sum V_i\geqslant 0$$
则有:
$$\sum(P_i\times ans - V_i)\geqslant 0$$
所以对于二分出的 $ans$,将每条边边权设置为 $P_i\times ans - V_i$,判断有没有负环即可。
温馨提示使用 bfs 版的 SPFA 判负环要超时,所以需要玄学之力 dfs 版 SPFA 判负环才能通过。
时间复杂度 $\mathcal O(\log(\frac{\max V_i}{\max P_i})\times 玄学)$。反正能在随机数据下过。
```cpp
#include <iostream>
#include <iomanip>
#include <cstring>
using namespace std;
constexpr int N = 7e3 + 5;
constexpr int M = 2e4 + 5;
int n, m;
struct Edge {
int ver, v, p;
} e[N + M];
int head[N], nxt[N + M], tot;
inline void add (int a, int b, int v, int p) {
e[++ tot] = Edge{b, v, p};
nxt[tot] = head[a], head[a] = tot;
}
double dis[N];
bool vis[N];
inline bool dfs (int x, double ans) {
vis[x] = true;
for (int i = head[x]; i; i = nxt[i]) {
int y = e[i].ver;
if (dis[y] > dis[x] + ans * e[i].p - e[i].v) {
if (vis[y]) return false;
dis[y] = dis[x] + ans * e[i].p - e[i].v;
if (!dfs(y, ans)) return false;
}
}
vis[x] = false;
return true;
}
inline bool check (double ans) {
memset(dis, 0x6F, sizeof(dis));
dis[0] = 0;
memset(vis, false, sizeof(vis));
return dfs(0, ans);
}
int main () {
cin >> n >> m;
for (int i = 1; i <= m; ++ i) {
int a, b, v, p;
cin >> a >> b >> v >> p;
add(a, b, v, p);
}
for (int i = 1; i <= n; ++ i) {
add(0, i, 0, 0);
}
double l = 0, r = 200;
constexpr double eps = 1e-5;
while (r - l > eps) {
double mid = (l + r) / 2;
if (check(mid)) r = mid;
else l = mid;
}
if (l) cout << fixed << setprecision(1) << l;
else cout << "-1";
return 0;
}
```
:::
:::info[[点菜](https://www.luogu.com.cn/problem/P1752)]{open}
有 $n$ 个人到一家餐馆点菜。这家餐馆总共有 $m$ 道菜,每一道菜都有两个属性——美味度和价格。这 $n$ 个人每周都会来一次,每次只会点一道菜或不点。在这 $n$ 个人中,有 $p$ 个人比较挑剔,他们只能接受美味度大于等于一定值的菜;有 $q$ 个人比较贫穷,他们只能点价格小于等于一定值的菜。现在请你计算:这些人至少要来几周,才可能能把餐馆的所有的菜都点过一遍?若来多少遍都无法点完,输出 $-1$。
$p+q \leqslant n \leqslant 5\times10^4,m \leqslant 2\times10^5$。
:::
:::success[思路 + 代码]{open}
对于答案 $wek$,显然用更多的周同样能点完所有菜,但是少任意量的时间都点不完。所以可以二分求解。
优先考虑挑剔的人,将菜品按照美味度从大到小排序,按要求的美味度从大到小处理每一个挑剔的人,由于需要考虑贫穷的人,贪心地优先吃更贵的菜,直到周数不够到或者没有能吃的菜了。然后考虑从价格要求从小到大处理贫穷的人,把所有剩下的菜从小到大排序,给当前考虑的贫穷的人吃尽可能多的他能接受的菜。最后再让没有限制的人处理剩下的菜,判断能否吃完所有的菜。
以上所有排序处理部分使用堆实现。
时间复杂度 $\mathcal O((n + m)\log m)$。
```cpp
#include <iostream>
#include <queue>
#include <algorithm>
#define int long long
using namespace std;
constexpr int N = 5e4 + 5;
constexpr int M = 2e5 + 5;
int n, m, p, q;
struct Dish {
int del, pri;
friend inline bool operator < (Dish A, Dish B) {
return A.pri < B.pri;
}
friend inline bool operator > (Dish A, Dish B) {
return A.pri > B.pri;
}
} d[M];
inline bool cmp1 (Dish A, Dish B) {
return A.del > B.del;
}
int mindel[N], maxpri[N];
inline bool cmp (int a, int b) {
return a > b;
}
priority_queue <Dish> tmp;
priority_queue <Dish, vector <Dish>, greater<Dish>> q2;
inline bool check (int wek) {
if ((n - p - q) * wek >= m) return true;
while (!tmp.empty()) tmp.pop();
int pos = 1, done = 0;
for (int i = 1; i <= p; ++ i) {
for (; pos <= m and d[pos].del >= mindel[i]; ++ pos)
tmp.push(d[pos]);
for (int j = 1; j <= wek and !tmp.empty(); ++ j) {
tmp.pop();
done ++;
}
}
if (done + (n - p - q) * wek >= m) return true;
while (!q2.empty()) q2.pop();
while (!tmp.empty()) {
q2.push(tmp.top());
tmp.pop();
}
for (; pos <= m; ++ pos) q2.push(d[pos]);
for (int i = 1; i <= q; ++ i) {
int cnt = 0;
while (!q2.empty() and q2.top().pri <= maxpri[i] and cnt < wek) {
q2.pop();
done ++;
cnt ++;
}
}
return (done + (n - p - q) * wek >= m);
}
signed main () {
cin >> n >> m >> p >> q;
for (int i = 1; i <= m; ++ i) cin >> d[i].del >> d[i].pri;
for (int i = 1; i <= p; ++ i) cin >> mindel[i];
for (int i = 1; i <= q; ++ i) cin >> maxpri[i];
sort(d + 1, d + m + 1, cmp1);
sort(mindel + 1, mindel + p + 1, cmp);
sort(maxpri + 1, maxpri + q + 1);
int l = 1, r = m, ans = -1;
while (l <= r) {
int mid = l + r >> 1;
if (check(mid)) r = mid - 1, ans = mid;
else l = mid + 1;
}
cout << ans;
return 0;
}
```
:::
完成[习题](https://www.luogu.com.cn/training/919310#problems)以巩固知识。
---
完结撒花!