题解:P5496 【模板】回文自动机(PAM)
cmleric
·
·
题解
回文自动机
意义
我们考虑这样一类问题,如何求一个字符串中不同回文串的数量?这时有人立即想到了 manacher,manacher 本质上利用了回文串的对称性来记忆化 + 暴力中心扩展来维护以某一点为中心的最长回文半径。但这仅限于长度,那么上述问题呢?如果沿用刚才的思路,再加上 BKDRHash,就可以获得一个 O(n^2) 的算法。这个算法在运算时并没有继承像 manacher 一样的运用回文串的对称性,那么考虑一个新算法来利用这一点,这就是回文自动机。
字典树的建立
奇回文树和偶回文树
像其他自动机一样 (说起自动机就想到 2025 CSP-S T3),我们要建立字典树来高效地维护或查询,但回文串分两种:长度为奇数和长度为偶数。manacher 通过插入字符统一转换为奇回文串来维护,我们的字典树空间本来就要占用很多,如果插入字符的话可能会炸,所以我们建一个森林,共有两棵树:奇回文树和偶回文树。
回文树的结构
我们尽量希望一种节省空间的方式,那么每个回文串我们只记录一半,例如奇回文串 \texttt{abcba}\to\texttt{abc},偶回文串 \texttt{abba}\to\texttt{ab},然后将他们穿在树上即可。\
读取方式:若为偶回文树,那么从根节点开始,每次直接在原有字符串的左右两端加上路径上的字符,一开始为空串;奇回文串由于最中间字符只有一个,所以根节点与子节点之间的路径读取时只作为单个字符,往后和偶回文树没有区别。
快速匹配模式
最长后缀回文串
我们想一下如何利用回文的对称性来快速构建这种回文树。我们发现,对于一个回文串来说,如果将其两端去掉,那么它仍然是一个回文串,那我们来倒推一下,发现如果一个字符串拼接了一个字符 \texttt{t},若想让它形成回文串,该字符串必须满足下面的条件(palidrome 是回文串的意思):
string = string1 + t + palindrome
然后
new \ palindrome = t + palindrome + t
那么我们只需要维护某一字符串的回文后缀就可以了,但是有一个非常好的性质,假设一个字符串的非最长后缀为 s_1,取一个比它更长的后缀 s_2,那么 s_1 一定是 s_2 的后缀,即后缀具有包含性 (我突然想到要是匹配的字符串都是这样的包含关系,是不是AC自动机的复杂度会退化啊),那么只需要维护一个最长的后缀回文串,那么剩下的后缀回文串都会被包含在里面。如果我们已知最长后缀回文串,那么我们就可以快速匹配了,匹配机制如下:
- 插入一个字符时找到前面字符串的最长回文后缀。
- 判断现在这个字符是否与最长回文后缀的前一个字符相等。
- 如果相等,那么匹配成功,接在该字符串上,记录。
- 如果不相等,那么将最长回文后缀作为字符串,找它的最长回文后缀,即原字符串的第 k 长的回文后缀,重复步骤 2 并向下。
建立缺少 fail 指针的回文树
我们按照上面的思路,与我们的回文树进行对接,看看在已经维护好最长后缀回文串的情况下如何建立回文树。
- 首先初始化根节点,让根节点 1 作为根节点 0 的最长回文后缀。
- 挨个插入字符并每插入一个字符执行一下步骤。
- 将该字符的最长回文后缀默认为根节点 0,这个非常重要,下面会说明原因。
- 判断前面字符串的最长回文后缀的前一个字符是否与现在的字符相等,如果相等,建边。如果不相等,那么就继续找,如果最后都没有相等的,那么肯定会到根节点 1,直接在奇回文树上建边作为根节点的直连边,单个字符作为一个回文串;如果发现在前面有一个字符刚好与现在字符相等,两个字符之间为空串,则会接在根节点 0 的偶回文树上,所以要初始化。
概括为下面几张图:
- 第三步的匹配,第一、二次匹配失败,第三次匹配成功:
- 单个字符的特殊情况:
- 两个字符的特殊情况:
如果你仍然对上述内容产生疑惑,请接着看完 fail 指针再来看这里。
fail 指针
许多同学都是在这里开始懵的,我也废了很长时间才弄明白,我将尽量清楚得讲解这一部分。\
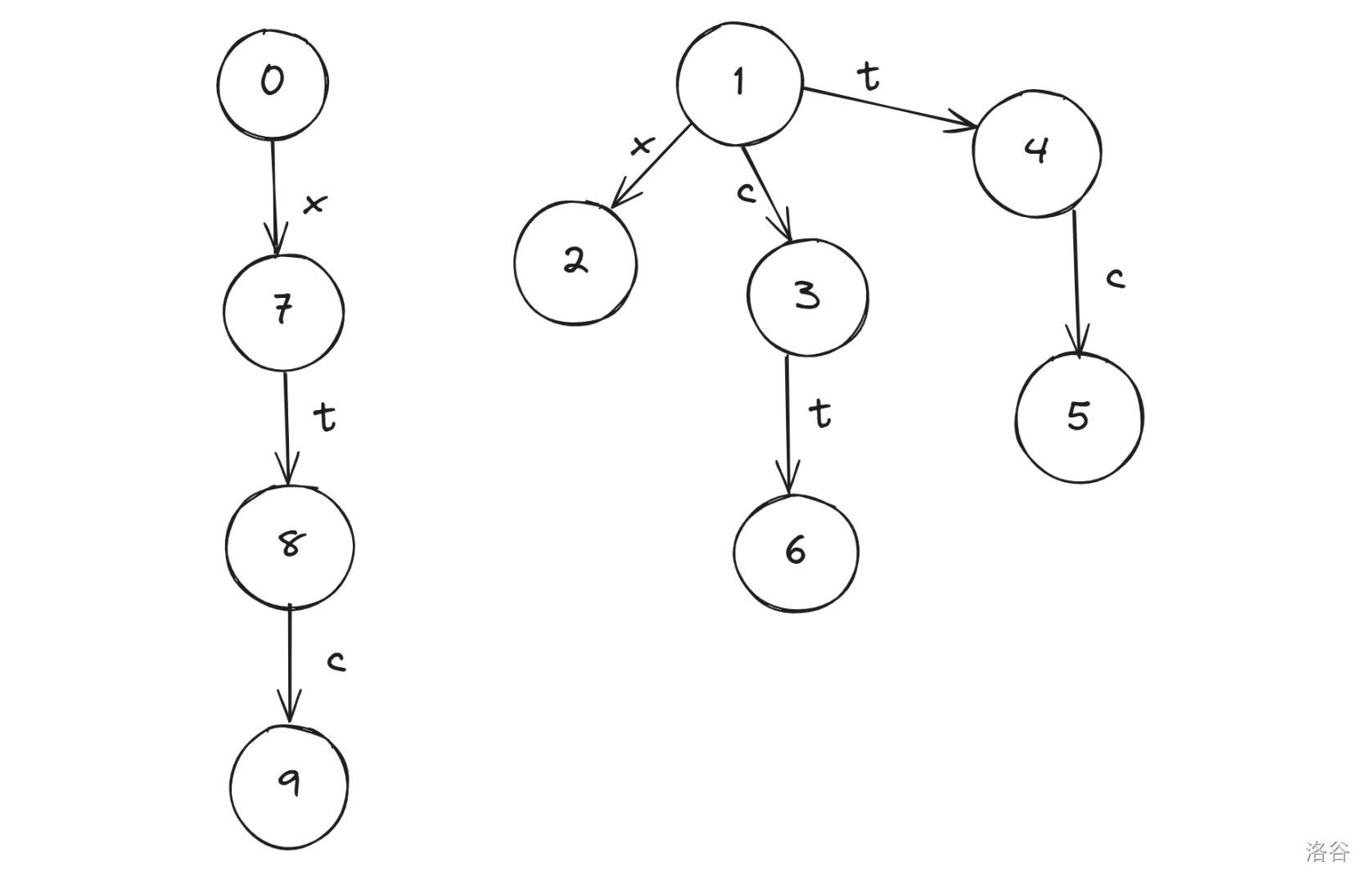
例如对于 $6$ 这个节点,它所代表的回文串为 $\texttt{tct}$,它的最长后缀回文串为 $\texttt{t}$,那么它的 $fail$ 指针就会指向代表 $\texttt{t}$ 这个回文串的节点,即 $4$;再举一个例子,$9$ 对应的节点回文串 $\texttt{ctxxtc}$,其最长后缀回文串为 $\texttt{c}$,那么它的 $fail$ 指针会指向代表 $\texttt{c}$ 这个回文串的节点,即 $3$。\
然后你会得到下面这张看起来十分复杂的图像(但仔细分析并不麻烦):
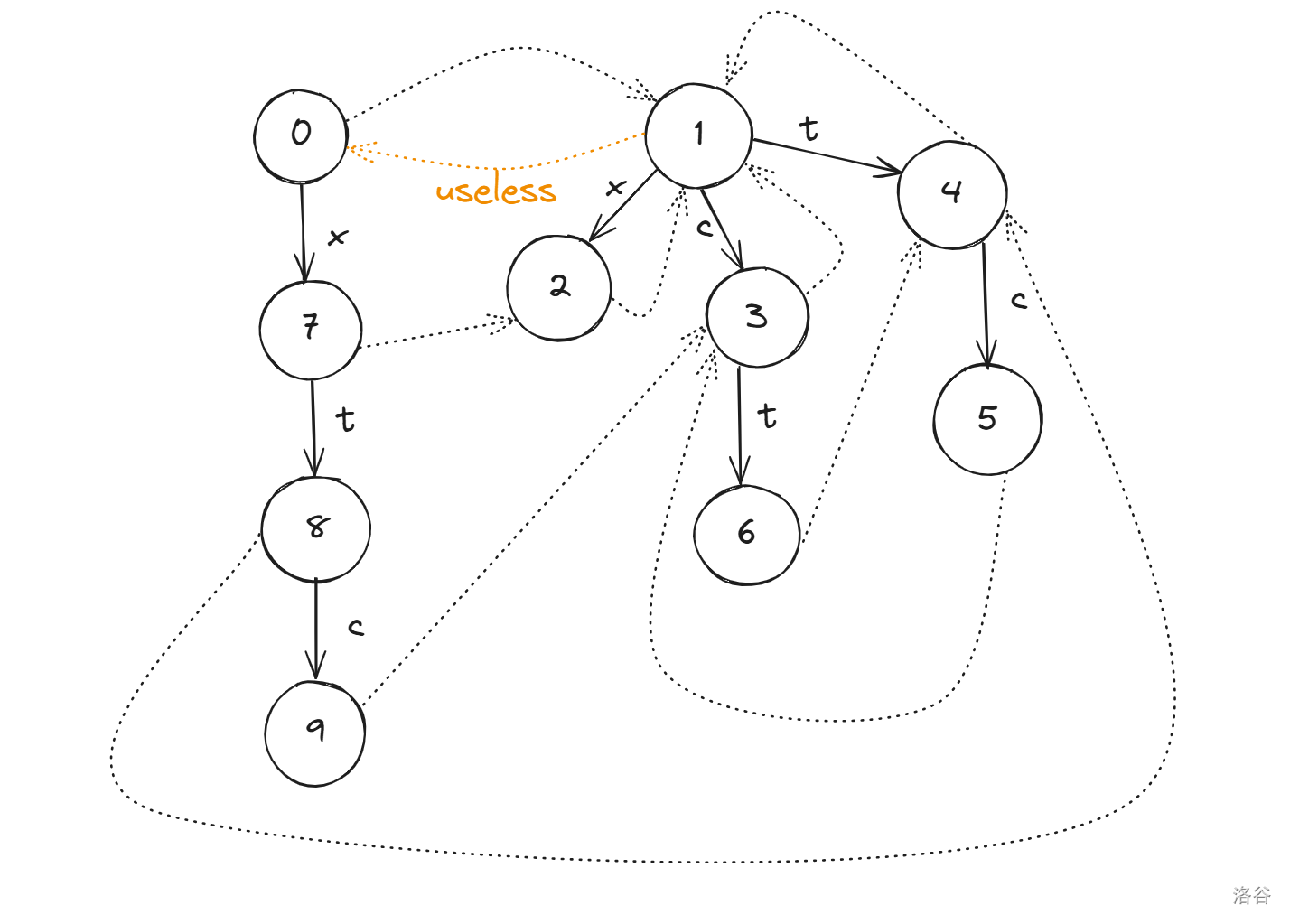
根节点 $0$ 的 $fail$ 指针接在根节点 $1$ 上,因为所有节点的 $fail$ 初始化为 $0$,如果前面没有和该字符拼成回文串的,那这个字符只能自己作为回文串,利用根节点 $0$ 的 $fail$ 指针跳到根节点 $1$ 上,如果仅仅是两个字符相等,那么有了初始化,就直接利用初始化的 $fail$ 跳到根节点 $0$ 上,这是两个特殊情况。\
那么我们现在来研究一下如何递推得到 $fail$ 指针,我们发现对于一个节点的 $fail$ 指针,它应是从父亲节点的 $fail$ 指针开始跳,直到可以满足与该节点形成回文串为止。为什么呢?首先,我们不可以从父亲节点开始跳,因为那样的话会返回原串,而我们要求的是后缀。即使是后缀,它也是回文串,所以说它也满足中间是回文串,两端加上字符的特点,且后缀的最后一个字符一定是我们新加入的字符。所以说要从新产生的回文串的开头往回找,找到第二个与最后一个字符相同的字符,然后这一部分就是最长回文后缀。不懂的可以看图:
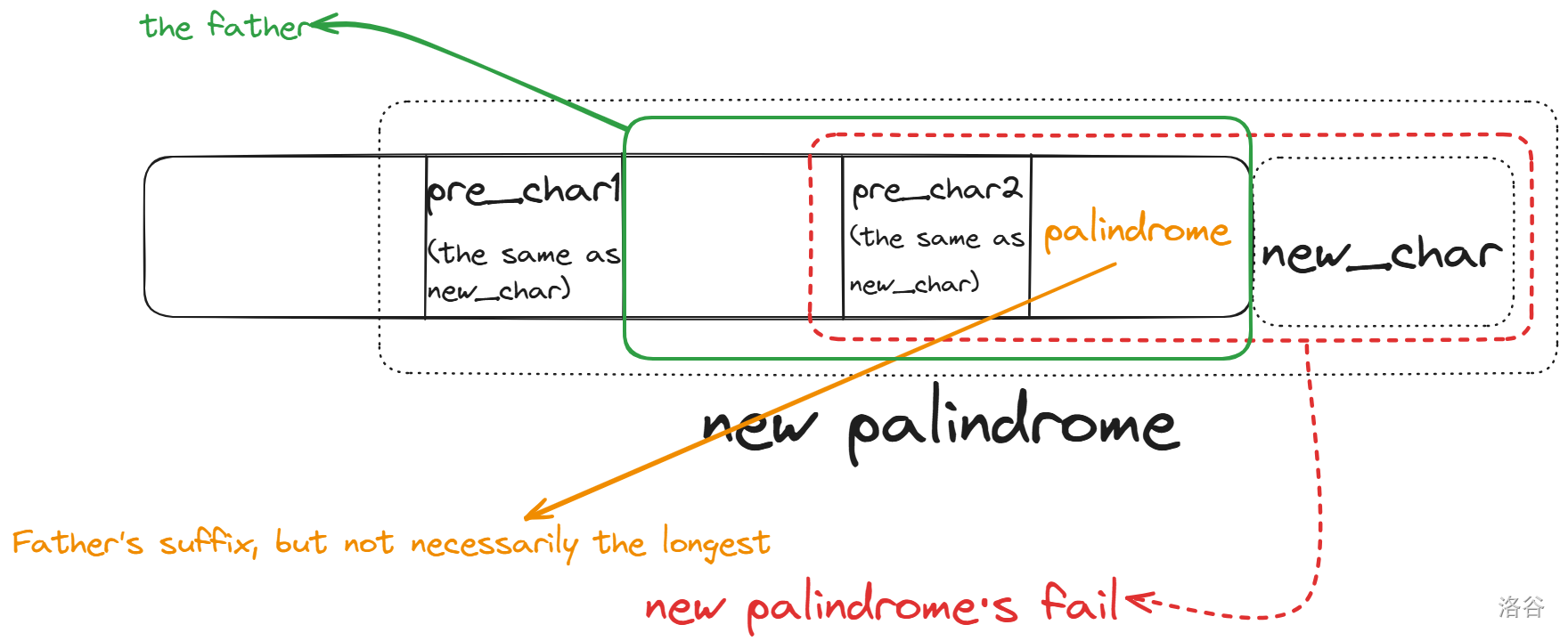
总的来说,就是字符 + 回文串 + 相同字符 = 回文串。
## 其他一些需要维护的东西
### 长度维护
对于每个节点,我们需要维护它的长度来求解一些东西,那么就需要从它的父亲节点推导过来:
$$now \ len = father \ len + 2$$
容易发现,在根节点 $1$ 的子节点的长度都为 $1$,因此按照公式,我们把根节点 $1$ 的长度设为 $-1$,$(-1) + 2 = 1$。根节点 $0$ 的长度就是正常的 $0$。
### 个数维护
在本题目中的个数是以该位置结尾的回文串个数来计算的,这个可以从 $fail$ 指针那里递推。由于 $fail$ 指针指向的是当前回文串的后缀,那么整个后缀链上的回文串都是以插入的当前字符结尾的,所以它的回文串个数也是 $fail$ 指针结尾的个数 $+ 1$,如果遇到要求不同回文串总数的就是节点数 $- 2$,反映到代码上就是 $cnt - 1$,因为节点下标是从 $0$ 开始的,如果遇到求所有回文串的数量的,在新开节点代码的外部加上求遍历到节点的以该节点为结尾的回文串的个数。
## 需要注意的东西
### 字符串下标
这个要重点注意,如果你代码调试全部输出 $1$,请检查下标访问!!!
### 求最长后缀回文串
注意匹配时可能出现下标 $<0$ 的情况,需要注意,详见代码。
## 算法的一些其他说明
1. 该代码比 manacher 的优势是可以强制在线并且可以求出本质不同回文串的个数。
2. 该代码复杂度大约是 $O(n)$,实际上比这个复杂度跑的慢,因为后缀跳跃需要时间。
3. 该代码继承了字典树的浪费空间的特点。
## Code
~~同机房大佬一直觉得很多题解马蜂太玄学,我就研究了一种容易理解的马蜂~~
```cpp line-numbers
#include<bits/stdc++.h>
#define MX 1000000
using namespace std;
struct node//建立字典树节点
{
int len,num,son[26],fail;
void init(int _len)//初始化,一般不用
{
fail = num = 0;
for (int i = 0;i < 26;i++)
{
son[i] = 0;
}
len = _len;
}
}tree[MX + 10];
int cnt,last,now,ans;
string s;
void initree()//初始化两个根节点
{
tree[0].init(0);
tree[1].init(-1);
tree[0].fail = 1;
cnt = 1;
}
int getfail(int p)//获得可以匹配的最长后缀回文串
{
while (now - tree[p].len - 2 < 0 || s[now - 1] != s[now - tree[p].len - 2])
{
/*这里注意下标,我并没有转换字符串输入方式,所以所有访问都要-1,并且注意now-tree[p].len-2<0的情况*/
p = tree[p].fail;//后缀跳跃
}
return p;
}
void add(char c)
{
now++;//记录新加入节点
int x = c - 'a',f = getfail(last);
if (!tree[f].son[x])//新开节点
{
tree[++cnt].init(tree[f].len + 2);//记录长度
tree[cnt].fail = tree[getfail(tree[f].fail)].son[x];//本篇代码的精髓
tree[cnt].num = tree[tree[cnt].fail].num + 1;//求以该字符为后缀的回文串个数
tree[f].son[x] = cnt;//记录子节点
}
last = tree[f].son[x];//总是记录最后一个节点
}
int main()
{
initree();//注意,有些人本地运行不出来是因为没有初始化字典树
cin >> s;
for (int i = 0;i < s.size();i++)
{
s[i] = (s[i] - 97 + ans) % 26 + 97;//神秘强制在线加密
add(s[i]);
ans = tree[last].num;
cout << ans << ' ';//输出结果
}
return 0;
}
```
## 例题
[P5685 [JSOI2013] 快乐的 JYY](https://www.luogu.com.cn/problem/P5685)
这道题目比较板子,就是求两个字符串的公共子串的回文串的数量,先对两个树分别建立回文树然后从根开始dfs就行,如果遇到可以同时转移的就记入数量,不可转移就退出\
**注意**
1. 十年OI一场空,不开____见祖宗
2. 注意字母是大写还是小写,不要用板子然后只写一个dfs
### Code
```cpp line-numbers
#include<bits/stdc++.h>
#define MX 1000000
using namespace std;
struct node
{
int num[2],fail[2],len[2],son[2][26];
void init(int _len,int d)
{
num[d] = fail[d] = 0;
for (int i = 0;i < 26;i++)
{
son[d][i] = 0;
}
len[d] = _len;
}
}tree[MX + 10];
long long int last[2],now[2],cnt[2],n[2],ans;
string s[2];
void initree(int d)
{
tree[0].init(0,d);
tree[1].init(-1,d);
cnt[d] = 1;
tree[0].fail[d] = 1;
}
int getfail(int p,int d)
{
while (now[d] - tree[p].len[d] - 2 < 0 || s[d][now[d] - tree[p].len[d] - 2] != s[d][now[d] - 1])
{
p = tree[p].fail[d];
}
return p;
}
void add(char c,int d)
{
now[d]++;
int f = getfail(last[d],d),x = c - 'A';
if (!tree[f].son[d][x])
{
tree[++cnt[d]].init(tree[f].len[d] + 2,d);
tree[cnt[d]].fail[d] = tree[getfail(tree[f].fail[d],d)].son[d][x];
tree[f].son[d][x] = cnt[d];
}
last[d] = tree[f].son[d][x];
tree[last[d]].num[d]++;
}
void getans(int d)
{
for (int i = cnt[d];i >= 0;i--)
{
tree[tree[i].fail[d]].num[d] += tree[i].num[d];
}
}
void dfs(int p1,int p2)
{
for (int i = 0;i < 26;i++)
{
if (tree[p1].son[0][i] && tree[p2].son[1][i])
{
ans += 1ll * tree[tree[p1].son[0][i]].num[0] * tree[tree[p2].son[1][i]].num[1];
dfs(tree[p1].son[0][i],tree[p2].son[1][i]);
}
}
}
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin >> s[0] >> s[1];
n[0] = s[0].size();
n[1] = s[1].size();
for (int i = 0;i <= 1;i++)
{
initree(i);
for (int j = 0;j < n[i];j++)
{
add(s[i][j],i);
}
getans(i);
}
dfs(0,0);
dfs(1,1);
cout << ans << '\n';
return 0;
}
```
题解到这里就结束了,祝各位 RP++,希望能对大家有所帮助(同机房大佬说我写的比较清楚),如果有什么错误请指正(毕竟我在写的时候就修改了许多前面的小毛病)。感谢同机房大佬 hyl 指导的 Markdown 和 $\KaTeX$。\
update at $2025.12.18$\
修正了在统计回文串个数时的表述并且加入了一些应用的题目