随机化算法相关
xie_T34
·
2025-04-15 16:01:05
·
算法·理论
前言
如有疏漏欢迎指出。后续可能会更新更多内容。
简介
随机化算法,一种神秘算法。你可以在各个地方找到随机化算法或者随机化技巧的存在,比如说 Treap 中为每个节点分配了一个随机的权值,使得树的形态不会退化成链,或者是并查集的随机合并,或者是纯粹的随机化算法,如爬山,退火,遗传等。
引入
我们来看一道很简单的题目:
给定一个范围 [l,r] ,其中 100000\le l\le r\le 999999 ,你需要对 [l,r] 中的数进行计数,条件:
设该数为 \overline{abcdef} ,那么你需要将 a,b,c,d,e,f 进行分组,每组 3 个元素,使得每组中的数字恰好构成一个合法的三角形。
一个比较暴力的做法是这样的:枚举 [l,r] 中的每一个数,随后将数拆分出来,并枚举全排列,前三个为一组,后三个为一组,只要有一组合法就统计进答案,然后停止枚举排列,去看下一个数。
我们浅算一下极限复杂度:9\times10^5\times 6!=6.48\times 10^8 。按照常识来讲是会超时的,然而洛谷机子快加上这样子的枚举肯定是跑不满的,实测可以通过。
那么有没有时间上稳一点的算法呢?有的兄弟,有的。随机化算法这不就来了吗?
随机化算法大部分都牺牲了代码的正确性 ,换来了较高的运行时间效率 和较低的码量 。大部分的随机化算法的出错率是可以算出来的,若出错概率在可接受的范围内,就可以使用随机化算法。你可以这么想,在原代码必定超时且暂时想不出正解 的情况下,这道题很有可能分数较低,但是如果采用了随机化算法,虽然正确性无法保证,但是你的运行时间得到了保证,如果你在打了部分分的基础上在大数据下采用随机化,真的就有可能会多得一些分数。
回到这道题,我们有什么随机化的头绪吗?注意到在暴力思路中,枚举全排列占了大量时间,我们是否可以考虑将原数随机排列,并只检查这些排列是否可以构成三角形。当然是可以的,以下是核心代码:
for(int i=1;i<=140;i++){
int u=rd(1,3);//表示在 1~3 的数字中随机选择一个
int v=rd(4,6);//表示在 4~6 的数字中随机选择一个
swap(a[u],a[v]);
if(a[1]+a[2]>a[3]&&a[1]+a[3]>a[2]&&a[2]+a[3]>a[1]&&a[4]+a[5]>a[6]&&a[5]+a[6]>a[4]&&a[4]+a[6]>a[5]){
ans++;
break;
}
}可以看见我们总共随机排列了原数共 140 次,筛选了所有情况的 \frac{7}{36} ,看起来很容易判断出错,但并不是每一个数字都只会有一种情况才能组成三角形的,只要有不低于于 5 种能够成功组成三角形的情况,成功的概率就会大大提高,配合上 IOI 赛制,多交几遍 AC 便不成问题。
进阶
随机化算法能够运用的一个重要条件便是其具有足够的正确率 ,注意不是正确性,所以我们也不能无脑地使用随机化算法,而是要先想一想:我能不能计算一下这个随机化算法的正确率?
其次,随机化算法也应该加入一些优化,这将大大增加其正确率。
我们以一道例题来说明:(来源:校内 NOIP 模拟赛)
现在你有 n 条信息,依次编号为 1\sim n ,第 i 条信息的大小为 a_i ,现在你需要将这 n 条信息划分为连续的 k 组,每一组占用的内存大小为这一组信息大小的总和。你可以使用一次压缩技术:选择一个数 x ,随后将所有 a_i 同时变为 (a_i+x)\bmod m 。
你需要求出一种划分和压缩的方案,使得内存占用最大的一组内存最小。
数据范围:
对于 30\% 的数据,有 n\le20,m\le50 。
对于 60\% 的数据,有 n\le 1000 。
对于 100\% 的数据,有 1\le k\le n\le10^5,1\le m\le1000,0\le a_i\le m 。
数列分段摇身一变,变成毒瘤来恶心你辣!
一种很暴力的思路就是枚举 x ,因为 1\le m\le 1000 ,所以直接枚举 1\sim m 之间的每一个 x ,然后用数列分段的方法二分解决即可,记得也算一下原数列的结果,这样子的时间复杂度是 O(nm\log n) 的。可以拿到 60 分的好成绩。
实际上这道题正常的解法也就到此为止了,这道题的标程都使用的是随机化算法,那具体怎么做到呢?
我们可以发现,我们在枚举 1\sim m 的过程中,枚举了很多不必要的 x ,比如数列 \{1,2,2,2,3\} ,当 m=10 时,x 在 1\sim 6 之间都没什么用,因为这不会改变任何一个数的大小,答案自然不会更小。
所以我们需要转变一下思路:如果我们随机遍历 x ,是不是就可以避免遍历到一堆无用的 x 呢?具体做法:我们生成一个 1\sim m 的序列,然后随机打乱它们,然后从头开始遍历,就能不重不漏地遍历完每一个 x 。但是问题还未解决:你怎么知道这个 x 是无用的呢?很简单,我们二分答案的右边界是一个极大值,而在第一次二分答案完成之后,很容易能看出更优的答案不可能高于第一次二分之后的答案,所以我们直接把二分答案的右边界设置成上一次二分完成之后的答案。同时设我们当前的答案是 ans ,那么我们在选择一个新的 x 之后,不要着急着去二分,先检查这个 x 能否划分出 ans-1 的答案,若不能则说明这个 x 不能使得答案更优,直接跳过就可以了。
那问题在于,这个随机化算法的正确率到底高不高?实际上这个算法的正确率极其高,第 i 次选择 x 得到更优答案的概率是 \frac{1}{i} ,因为权值就是 1 ,所以更优答案的期望就是 \sum \frac{1}{i} 。这是一个调和级数,那么我们期望只会二分 O(\ln m) 次,总的时间复杂度就是 O(m\times n+n\ln m\log n) 。完全可以通过。
如何证明?我们来画个图就可以了。我们容易得知答案区间为 0\sim n\times m :
因为随机打乱,我们期望的 x 会是平均分布的,那么我们期望的答案也会是平均分布的。所以第一次二分结束,我们会将答案区间分成这样:
此时我们再选择一个 x ,就有 \frac{1}{2} 的概率选择到更小的答案区间,此时我们会将答案区间再次缩小,因为期望平均分布,那么更优答案区间会缩小到原来的 \frac{1}{3} 。以此类推即可。
这下我们便能了解到随机化算法的一个特性:通过随机打乱等操作,让样本能够尽可能地覆盖住每一个情况,可谓是“以偏概全”。我们再来看一个例题:(来源:校内 CSP-S 模拟赛)
现有 n 个糖果,每个糖果有两个数值为美味度 a_i 和美观度 b_i 。现要拿出不超过 \lfloor \frac{n}{2} \rfloor + 1 个糖果使得它们的美味度之和以及美观度之和大于所有糖果美味度的和以及美观度的和的二分之一,输出所取的编号,顺序任意。若无解,输出 -1。有 spj。
数据范围:1\le n \le 10^5 ,a_i,b_i \le 10^9 。
这道题对于随机化很一眼了,直接随机打乱序列,随后为了让我们选取的所有糖果能够更有概率符合条件,我们直接取 \lfloor \frac{n}{2} \rfloor + 1 个即可,那么就是随机打乱,随后算答案,只要符合条件就立马输出方案。具体就不细讲了。当然,这道题正解肯定是贪心之类的啦,不像上道题是真玄学。
至此我们又能发现随机化算法的一个特点:经常用于解决最优性问题 。
启发式算法
上述三道题的随机化算法看起来都很朴素,都是随机乱搞一通,似乎这一次随机出来的答案与上次随机出来的答案之间没有丝毫的关联,靠的是量变产生质变解决问题的。而此处便是特化之后的随机化算法,两个随机出来的解之间有着一定地关联,并且定向地向最优解靠拢。
像这种通过一个初始解以及产生新解的函数得到的一系列与上次产生的解有着关联的算法结构,我们一般称之为“邻域搜索”。这个名字就很贴切,一眼就能看出这种算法的在一个解的旁边产生新解的特性。具体来说,邻域搜索算法的过程都是从一个或一组初始解出发,在算法的参数的控制下通过自定义函数产生若干邻域解,随后按该算法自定的接受准则更新当前状态,而后按参数修改准则自调整参数。如此重复上述步骤直到满足算法的收敛准则,最终得到问题的优化结果。
不同的算法有着不同的参数,不同的接受准则以及不同的调参准则,自然也各有所长各有所短。
启发式算法通常在可观的代价下给出一个待解决问题的可行解,这个解也许就是最优的,也许不是,甚至可能是较劣的。与其相对应的最优化算法则是会精确地求出该问题的最优解。但通常来讲,最优化算法的实现都过于复杂且难度大,甚至有些题目还没有所谓的最优化算法,而如果我们能接受一个与最优解偏离不大的可行解,那么启发式算法就会方便得多。
反映到 OI 上,某些题目的正解过于复杂,编写难度大,但是如果我们不奔着 AC,而是以一种骗分的思想去写这道题,那么你就可以尝试尝试启发式算法,也就是下文会介绍到的模拟退火。
爬山算法
思想很简单:我们先随机生成一个解,然后根据生成的解在其附近生成新解,若新解更优,则将答案转移,下次则依靠该解生成新解。显然,这样子会陷入局部最优解,而有些问题的局部最优解并不是全局最优解。
总的来说,爬山算法就像是走上了一条不归路,只顾眼前的利益,哪个好就选哪个,最后得到最好的结果。
答案函数为单峰函数时可以使用,但答案函数非单峰时极为容易陷入局部最优解当中。
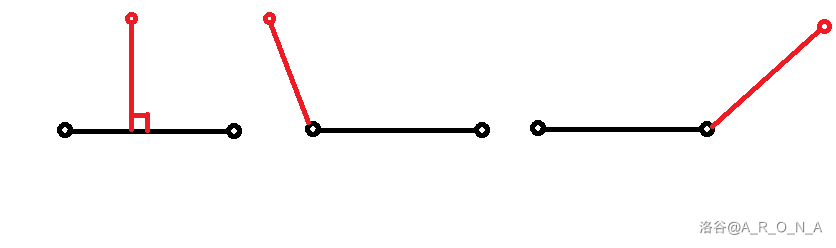
下面这张图能够展示爬山算法的过程:
可以发现爬山算法是定向地朝着最优解前进的,不过有时候会错过最优解的区间,这个时候就会往回跳回去,因为其生成新解的时候是会进行比较的,所以每一个被采纳的解只会比旧解更优。问题在于如何生成新解?
首先我们可以先随机取一点,随后我们可以像倍增一样,跳跃的幅度从大变小 ,每次跳的位置越来越精确,那么就越容易靠近最优解。我们一般称这个方法为控温 。
一般来讲,爬山算法都有三个参数:初始温度 T ,结束温度 T_0 ,温度变化率 \Delta T ,其中 T 较大,而 T_0 是一个略大于 0 的数字,\Delta T 是一个略小于 1 的数字。我们每次生成完一个新解,就使得 T\leftarrow T\times \Delta T ,直到其小于 T_0 ,而我们的跳跃幅度就由 T 来决定。
很明显,T_0 越小,我们的最优解就越精确。
爬山算法的局限性比较大,并且可以被三分法在一些简单的题目中替代掉,故用处不是很大,除非是极其复杂的单峰函数题,爬山才有出场的空间,而此时模拟退火又能代替爬山。
例题:
三分。
爬山算法练习题,先生成一个 x ,计算对应的 f(x) ,然后判断解是否更优,往上跳就好了。
double f(double x){
double ret=0;
for(int i=n;~i;i--){
ret+=pow(x,i)*a[i];
}
return ret;
}
double l,r,ans,fx;
void CM(){//初始状态可以定义成值域的中点,最大化利用变化率
double tmp=f(ans),ret=ans;//本次爬山出来的最终答案存储于此,现在先存初始状态
double T=1e3;
while(T>=1e-10){//精度拉高一些
double nowx=ans+(rand()*2-RAND_MAX)*T;//这样子可以让生成的解的变化量有正有负
if(nowx<l)nowx=l;//超范围直接拉回来就行
if(nowx>r)nowx=r;
double res=f(nowx);
if(res>tmp){
tmp=res;
ret=nowx;
}
T*=delta;
}
if(tmp>fx){
fx=tmp;
ans=ret;//小优化:和之前爬山求出来的答案作比较取最优,提高正确率
}
}模拟退火
应该是最广为人知的随机化算法?每年 CSP 前都会有人去学这东西,但每年考完都会发现这东西屁用没有。也不知道是哪些人把模拟退火吹得有些太过了。
上文所述爬山算法,缺点在于只会往更优解跳,非常容易陷入局部最优解当中,那如果我的函数长这样你不就炸了吗?
模拟退火应运而生。
模拟退火算法为什么被称为模拟退火,是因为其过程模拟了现实生活中的金属退火工艺,详情可以见百度百科。简单来说就是在退火过程中随着温度的逐渐降低,物体中分子的运动更加趋于稳定,最后达到一个理想的稳定状态。体现在算法中就是我们生产解的范围逐渐稳定,最后达到理想解,你会发现这和爬山算法是差不多的。但是模拟退火解决了爬山算法只会向更优解出发的问题。模拟退火的劣解不会被直接弃掉,而是会有一定概率 将当前解转移过去,但不转移答案 ,也就是说 f(x) 中只转移 x ,当前存储的答案仍然是刚刚的更优答案。那么这个“一定概率”到底是怎么个“一定概率”法呢?根据金属退火工艺的过程可知,这个“一定概率”肯定是随着温度的降低而降低的,从而达到我们期望的“逐渐稳定”的效果。
模拟退火采用了 Metropolis 接受准则以到达这个效果。
Metropolis 接受准则的内容大概来讲是这个样子的:设当前状态为 i ,生成的新状态为 j ,若新状态的内能小于旧状态的内能,则接受 j 作为当前的状态,否则以概率 \exp^{(\frac{-(E_j-E_i)}{kT})} 接受新状态 j 。其中 k 为 Boltzmann 常数,值为 1.38\times 10^{-23} 。T 则是当前的温度。也即物体粒子在温度 T 下趋于平衡的概率为 \exp^{\frac{\Delta T}{kT}} 。使用符号语言表达即为:
p=\begin{cases}1 & \text{if } E(x_{new})<E(x_{old})\\ \exp^{-(\frac{E(x_{new})-E(x_{old})}{kT})}&\text{if } E(x_{new})\ge E(x_{old})\end{cases}
看起来很晕啊,不过你可以选择记住这个结论,毕竟也挺短的。那么如何在代码上体现这个概率转移?众所周知,函数 f(x)=e^x 的取值范围:
当 x>0 时,f(x)>1 。
当 x\le 0 时,0<f(x)\le 1 。
因为上面的式子中分子为负数,故保证了 0<f(x)\le 1 ,我们需要做的就是将其与一个 [0,1] 的随机实数进行比较,那么在代码中的转移应该看起来像这个样子:
double de=newans-nowans;
if(de<0)//状态更优直接转移
else if(exp(-de/t)*RAND_MAX>rand())//概率接受转移因为 k 是常数,我们在代码里面可以忽视掉 k 。将这个式子牢牢记住,你就可以解决 50\% 的模拟退火问题了。
为什么是 50\% 呢?仔细观察上述代码,你会发现当 newans<nowans 时我们认为新解更优,也就是说我们认为解越小越好,所以遇到那些求最大的题目我们需要变式:
double de=nowans-newans;
if(de<0)//状态更优直接转移
else if(exp(-de/t)*RAND_MAX>rand())//概率接受转移这样子你就可以解决 99\% 的模拟退火问题了。为什么不是 100\% 呢?因为运气不佳啊,伙计。
刚刚说的是转移,接下来才是模拟退火。
模拟退火解一道题的步骤:
确定样本空间。
确定你要退火的函数。
设定合适的温度值。
开始搞玄学。
输出答案。
一道题中对函数进行模拟退火的步骤:
确定一个初始状态,并先计算其所对应的函数值。
开始对状态进行退火,一般采用随机扰动的策略。
得到新状态,计算对应函数值。
计算两个值的能量差。
随后按 Metropolis 接受准则接受新状态。
降低温度,重复上述操作直到温度够低。
退火完成,保存当前最优解。
算法特性:模拟退火算法与初始值无关,算法求得的解与初始解状态无关,模拟退火算法具有渐近收敛性,已在理论上被证明是一种以概率收敛于全局最优解的全局优化算法,模拟退火算法具有并行性。同时模拟退火也是解决 NP 问题的一个有效手段。
再来看模拟退火温度的三个参数,它们各自有什么作用呢。
模拟退火算法的时间复杂度为 $O(T(n)\times k)$,其中 $T(n)$ 是计算解所对应的答案所需要的时间复杂度,$k$ 是总迭代次数,$k$ 很难具体算出,一般会在程序里面自我调试出合适的参数。空间复杂度为 $O(1)$,模拟退火算法并不需要额外的空间,它本身只是提供了解的产生和筛选过程,额外的空间复杂度应该是由计算解的过程产生的。
模拟退火算法的优化:
1. 一般采用多次退火的策略,提高获取全局最优解的概率。
2. 可以比较多次退火产生的解,选取最优的一个,而不是取最后一次退火的解,时间复杂度不会增加,正确率能够显著提升。
3. 在一些多峰但峰值比较接近的函数的情况下,退火不容易跳到最优解上面去,这个时候会选择在退火完成之后利用 $T_0$ 或较小的温度进行随机扰动多次。
4. 多次退火时,初始解有两种选择,一种是选择在值域中点,一种是选择从上次退火完成之后的解继续退火,前一种方法的好处在于覆盖面更广,但是正确率也会有所下降,后面一个方法的好处在于如果离最优解很近,就有很大概率一次就跳过去,但是如果离得很远的话就没有跳过去的机会了,除非提高初温。一般我们选择后一种方法。
5. 多次退火时,使用不同的随机种子,有奇效。
模拟退火和爬山算法一般都会用于较难的计算几何问题,也会用于一些序列排列问题。但对于序列排列问题,大部分都只是随机化搜索加了个接受准则而已,貌似序列排列问题似乎很难与温度扯上关系?
**例题:**
[SP4587](https://www.luogu.com.cn/problem/SP4587):
平面直角坐标系上有 $n$ 条线段,全部平行于 $x$ 轴或 $y$ 轴。现在请你求出一点 $(x,y)$,这一点需要向其他所有的线段连线(连在任意地方都可以,包括端点),使得连线总长度最短。
其实这是个二维的单峰函数。
退火函数本身是好写的,来想如何使得连线最短:
忽略掉另外一维,也就是压成一维。如果点在线段之内,那么根据垂线段最短,直接连垂线,否则向最近的端点连线。
```cpp
double getdis(double _x1,double _y1,double _x2,double _y2){
return sqrt((_x1-_x2)*(_x1-_x2)+(_y1-_y2)*(_y1-_y2));
}
double calc(double nowx,double nowy){
double ret=0;
for(int i=1;i<=n;i++){
if(a[i].x1<=nowx&&nowx<=a[i].x2&&a[i].y1==a[i].y2){ret+=fabs(nowy-a[i].y1);continue;}
if(a[i].y1<=nowy&&nowy<=a[i].y2&&a[i].x1==a[i].x2){ret+=fabs(nowx-a[i].x1);continue;}
if(nowx<a[i].x1&&a[i].y1==a[i].y2){ret+=getdis(nowx,nowy,a[i].x1,a[i].y1);continue;}
if(nowx>a[i].x2&&a[i].y1==a[i].y2){ret+=getdis(nowx,nowy,a[i].x2,a[i].y1);continue;}
if(nowy<a[i].y1&&a[i].x1==a[i].x2){ret+=getdis(nowx,nowy,a[i].x1,a[i].y1);continue;}
if(nowy>a[i].y2&&a[i].x1==a[i].x2){ret+=getdis(nowx,nowy,a[i].x1,a[i].y2);continue;}
}//分讨
return ret;
}
void SA(){
double T=2009;
while(T>=1e-10){
double nowx=(ansx+(rand()*2.0-RAND_MAX)*T)*1.0;
double nowy=(ansy+(rand()*2.0-RAND_MAX)*T)*1.0;
if(nowx<lx||nowx>rx||nowy>uy||nowy<dy){T*=delta;continue;}
//这里的四个变量分别是最左端,最右端,最上端,最下端,可以证明点坐标超出这几个变量时一定不优
//所以超出了就直接跳过,但是注意降温,不然后面一直跳过一直跳过就浪费时间了
double nowans=calc(nowx,nowy);
double De=nowans-ansdis;
if(De<0){
ansx=nowx;
ansy=nowy;
ansdis=nowans;
}else if(exp(-De/T)*RAND_MAX>rand())ansx=nowx,ansy=nowy;
T*=delta;
}
}
```
[P2210 Haywire](https://www.luogu.com.cn/problem/P2210)
关于序列的题。
因为是在序列上面做操作,所以温度就和生成新解的变化量无关了,但是我们依旧可以使用 Metropolis 接受准则。
```cpp
int sum(){
int ret=0;
for(int i=1;i<=n;i++){
for(int j=1;j<=3;j++){
ret+=abs(pos[i]-pos[a[i][j]]);
}
}
return ret;
}
void SA(){
double T=1e5;
while(T>1e-12){
int nx=rand()%n+1,ny=rand()%n+1;//随机交换两个数,这就算是生成了一次新解
swap(pos[nx],pos[ny]);
int newsum=sum();
int de=newsum-now;
if(de<0){
now=newsum;
}else{
if(exp(-de/T)*RAND_MAX<rand()){
swap(pos[nx],pos[ny]);
}//如果不接受这个解就给它换回去
}
T*=delta;
}
}
```
[P5544 炸弹攻击](https://www.luogu.com.cn/problem/P5544)
个人认为最神的一道退火题,比平衡点那道更好,属于进阶型的题目。
按计算几何的套路我们对坐标 $(x,y)$ 进行退火,函数值就是当前 $(x,y)$ 能够炸多少人,因为有建筑的限制,我们能够很轻易地算出半径 $R$,随后算能炸几个人就好了。
但是这样你就会发现一个问题:这个函数值是个整数。
一般的计算几何的二维函数构成的图像就很平滑,像那种小山包一样是高低起伏的,没断层。但是这个函数构成的图像就很地狱,全是断层,~~你可以想象一下 MC 里面你在一个大平原里面突然看见一个大石柱子~~,它特别地不平滑,就算是退火你也很难跳出局部最优。我们需要思考的是如何让函数变得更加平滑,那么半径 $R$ 会是一个完美的选择。如果函数值是最大的 $R$ 使得这个圆不会碰到任何一个建筑,这个函数明显平滑得要命。那么我们考虑构造一种函数值形如 $xR+cnt$,其中 $cnt$ 为当前半径为 $R$ 时可以炸到多少个人。$x$ 为待定系数,让断层过渡尽量平滑。~~所以说这道题调参除了退火的三个参还得调个 $x$,麻烦死了~~。
那么这道题的计算函数就很显然了:
```cpp
pair<double,int>calc(double nowx,double nowy){
int ret=0;
double nowR=R;//题目限定的最大半径
for(int i=1;i<=n;i++){
double d=getdis(nowx,nowy,x[i],y[i]);//这个函数就是勾股求距离啦
nowR=min(nowR,d-r[i]);
}//计算最大的半径使得这个圆不会碰到任何一个建筑
nowR=max(nowR,0.0);
double mn=1e18;
for(int i=1;i<=m;i++){
double d=getdis(nowx,nowy,p[i],q[i]);
mn=min(mn,d-nowR);
if(d<=nowR)ret++;//计算人数
}
return {-max(mn,0.0)*C+ret,ret};//返回两个值方便判解和更新答案,C 就是我们待定的系数
}
```
退火函数还是一样的板子,就不给出代码了。
## 蚁群算法
模拟自然界中蚂蚁觅食的行为,蚂蚁向着食物前进时,会在其经过的路径上释放一种信息素,并能够感知其它蚂蚁释放的信息素。我们认为信息素浓度的大小代表路径的远近,信息素浓度越高,对应的路径距离越短。众所周知,蚂蚁是一类群居动物,而信息素浓度高又恰好说明走这一条道路的蚂蚁会比走其他道路的蚂蚁更多,那么当前的这一只蚂蚁就会有更大的概率沿着信息素浓度高的路径走。而此时的蚂蚁又会释放出新的信息素,导致浓度继续升高,最后便找到了一组理想中的最优解。当然,信息素肯定是会蒸发的,就像模拟退火会降温一样,这样子才能控制解的转移,也符合自然规律。然后,随着时间的推进,较短的路径上累积的信息素浓度越来越高,选择该路径的蚂蚁个数也越来越多。最终,整个蚁群会在正反馈的作用下集中到最佳的路径上,此时对应的便是问题的最优解。
你会发现蚁群算法和模拟退火有着很大的不同,它貌似并不是很适用于计算函数类?一般来说,蚁群算法用于图上问题,比如 TSP 问题之类。
由上可以看出,蚁群算法在 OI 中的应用并不是非常多,更多地是在现实生活中解决一些路径规划问题,所以这里给出两篇博客,可以下来自行阅读:
[数学建模——蚁群算法](https://blog.csdn.net/weixin_43848614/article/details/107999963)。
[题解 P1171](https://www.luogu.com.cn/article/2dovsbm1)。