一般图最大匹配学习笔记
lanos212
·
·
题解
前言
下文中的 N 表示全图点数,M 表示边数。
众所周知,二分图最大匹配可以在 O(NM) 的时间复杂度内使用增广路算法解决。
虽然使用网络流建模解决二分图匹配可以获得更加优秀的复杂度,但是它很难被沿用到一般图上的匹配问题。
对于一般图最大匹配的开花算法/带花树算法,我们可以看作是一种增广路算法上拓展得到的算法。
如果已经熟练掌握二分图与一般图的关系,了解开花算法以处理奇环为主,可以直接跳至开花算法/带花树算法部分。
二分图匹配时遇到已访问点
先给出增广路的定义。
增广路是一条路径,起始点未被匹配,终点未被匹配,中间经过的边以非匹配边与匹配边交替出现。
也就是长下面这样子的:(图中黑点表示被匹配点,白点表示未匹配点,特别加粗的边为匹配边)
我们回顾一下增广路算法的可行性是怎么保证的。
首先,我们运用了增广路定理:当图上不存在增广路时,得到最大匹配。
而在二分图上,找增广路时遇到已经访问过的点比较好处理,如下图。
如果遇到已经访问过的点,存在上图中的两种情况:
- 当前增广路出现环,发现此时把环去掉仍然是一条增广路,所以遇到已访问的点就不用访问了。
- 走到之前已经增广失败的点,发现此时继续走下去也一定无法增广,这种已访问点也无需访问。
综上所述,做二分图最大匹配时,搜索到已访问的点可以直接忽略,继续往别的点找增广路。
一般图匹配遇到已访问点
那么一般图匹配是不是也是都可以直接忽略呢?
显然不是,不然就可以用增广路算法做一般图匹配了。
我们不妨在一般图上考虑上面的情况。
注意,一般图和二分图的区别在于一般图存在奇环,我们会着重考虑奇环带来的影响。
我们还是考虑像二分图那样的两种情况:
- 当前增广路出现环,发现环一定是偶环,这与二分图中相同。
- 走到之前已经增广失败的点,如形成偶环走下去不能匹配,形成奇环走下去可能还能匹配。
这样我们只需要考虑经过奇环该怎么处理。
开花算法/带花树算法
先引入一个在搜索增广路时需对每个点记录一个值 vis。
我们将搜索增广路时经过边抠出来形成一颗生成树。(例图在下面)
- 当我们还没有访问到一个点 x 时,vis_x=0。
- 当一个点 x 在生成树上距离起始点长度为奇数时,vis_x=2。
- 当一个点 x 在生成树上距离起始点长度为偶数时,vis_x=1。
为了方便一个点向起始点回跳,我们还需要对每个点记录一个值 pre。
当然,我们还要记录每个点和谁匹配。对于一个已匹配点 $x$,它匹配了 $match_x$ 这个点。
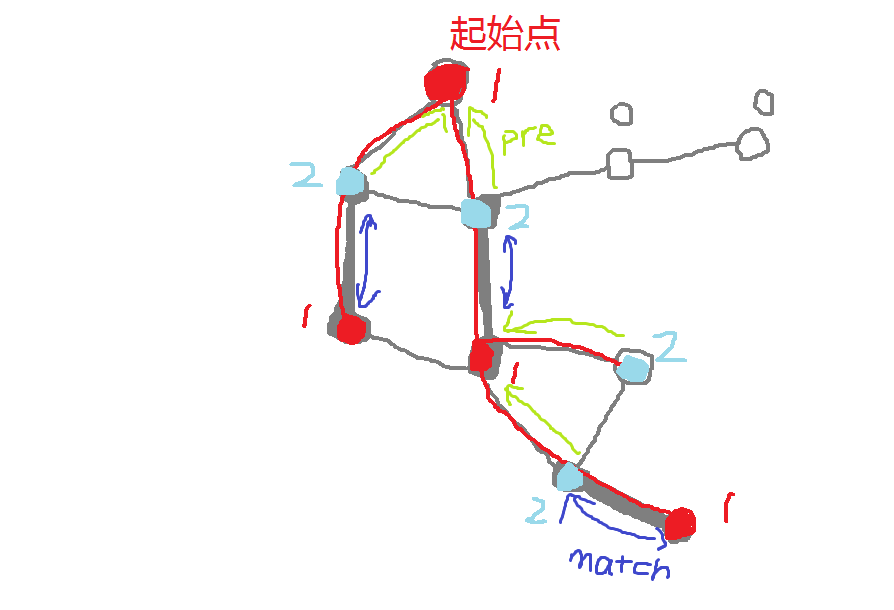
这个算法中,我们采用**宽度优先搜索**(BFS)来搜索增广路,以便于后面的操作。
注意,我们在 BFS 的过程中,进入队列的**只有 $vis=1$ 的点**。
我们可以先类似增广路算法去直接搜索增广路,那么我们需要处理这几种情况:
#### 到达的点 vis=2
这种情况形成了二分图最大匹配时出现的偶环问题,我们按照增广路算法的思路,不去管这个点。
#### 到达的点 vis=0,未匹配
找到增广路了,整条增广路翻转后结束搜索即可。
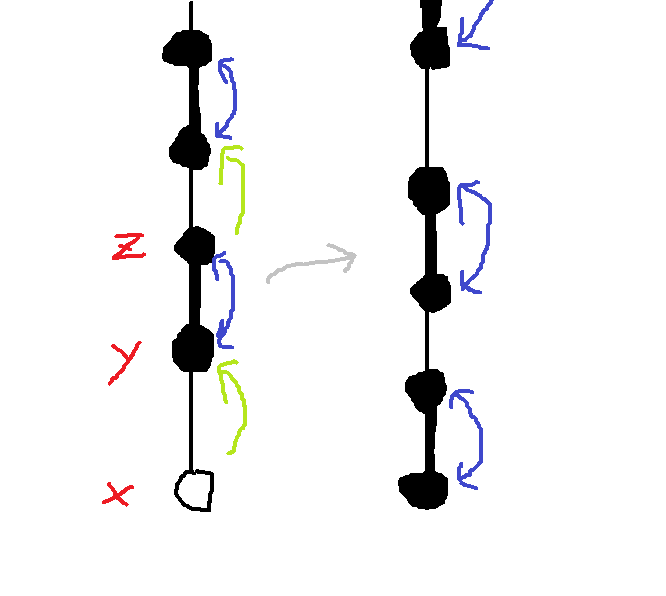
对于具体实现,我们找到到达的点为 $x$,然后不断做下面的操作直到跳到起始点:
- 找到上一个点 $y$,上上个点 $z$,然后将 $match_x$ 改为 $y$,将 $match_y$ 改为 $x$,再让 $x$ 跳到 $z$ 的位置继续操作。
由于只有 $match$ 是对不同搜索过程共用,而别的记录的值都只用于当前起始点的搜索,所以我们只需要修改 $match$ 的值。
#### 到达的点 vis=0,已匹配
这个时候可以直接将到达点 $x$ 所匹配的点 $match_x$ 扔入队列,将 $vis_x$ 改成 $2$,将 $vis_{match_x}$ 改成 $1$。
#### 到达的点 vis=1
我们发现此时出现了奇环,而这个奇环上的边一定长成这个样子:
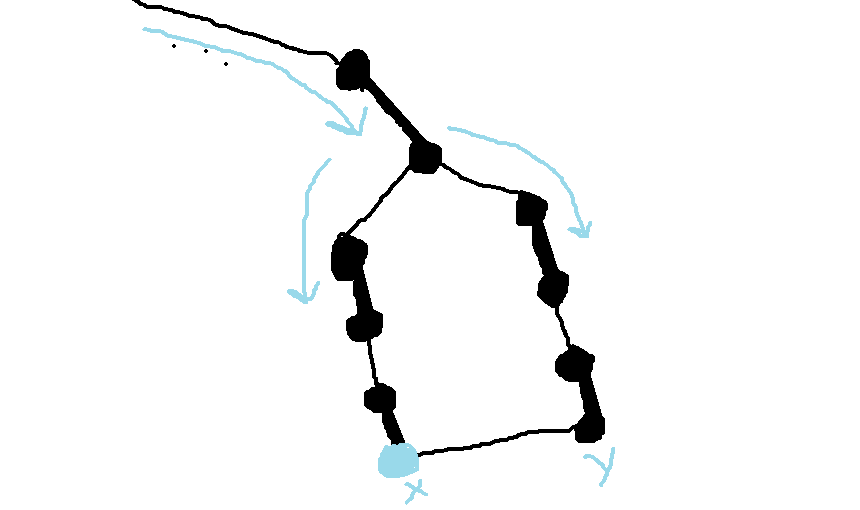
进入奇环的那条边一定是匹配边,之后两边以非匹配与匹配边交替。
而对于这种奇环,我们将整个奇环缩成一个点,不影响我们继续寻找增广路(这个点我们称为花,缩点的过程称为开花)。
因为对于任何一条进入奇环的出去的增广路,都可以对应一条经过花的增广路,同时一条经过花的增广路,也可以对应一条进入奇环出去的增广路,具体可见下图中的两个不同方向的例子:
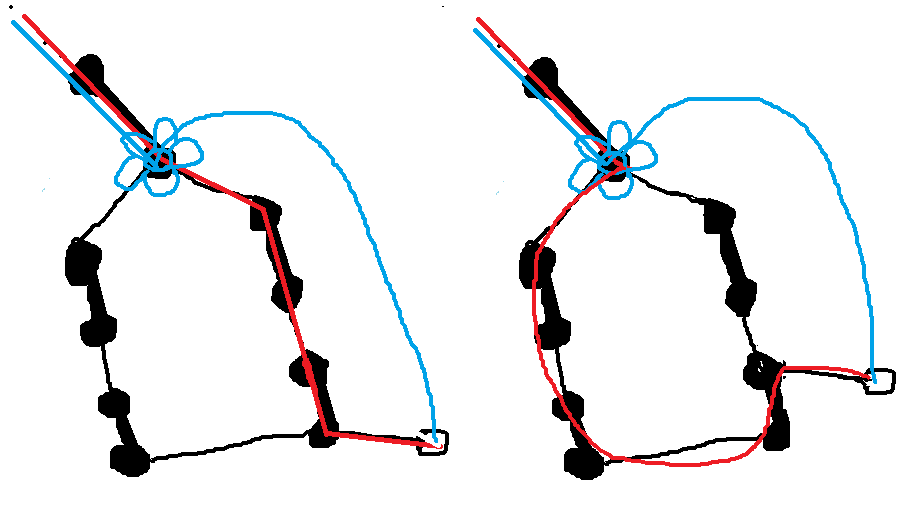
为了方便,我们缩点后的花实际放在奇环距离起始点最近的那个点上,我们称之为根。
下面是关于开花的具体实现方式。
对于缩点后图上边的问题,需要分两种考虑。
1. 环外到环的边,这些边我们在缩点后会将所有连出去的点都入队,可处理掉出环时的问题;缩点后用并查集维护当前点所在根,这样从外面走进环可以直接通过并查集找到根。
2. 环内的边只需要修改所有非匹配边,使得与根相连的点 $pre$ 连向根,其余的 $pre$ 在两个非匹配边间互相连对方,这样每个环上的点都能通过先跳向 $match$,再跳向 $pre$ 的方式到达根,可以结合下图中的两个不同方向的例子理解。
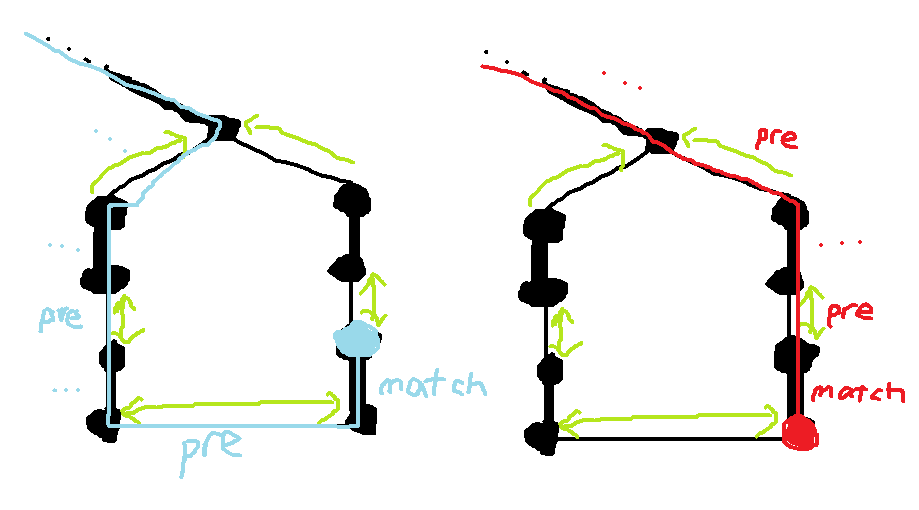
注意到上面两种处理对环外走回环然后从根回去提供了截然不同的两种路线,一种是慢慢绕环,一种是直接并查集跳到根。
这两种是有区别的,慢慢绕环我们会在找到增广路后翻转时用到,直接并查集跳到根我们会在下面找花的根用到。
现在我们还剩下如何求花的根。
如果我们现在在点 $x$,要走到 $vis=1$ 的点 $y$,那么根就是 $x$ 和 $y$ 在生成树上的 LCA。我们可以让 $x,y$ 轮流向上跳,跳的方式是先跳 $match$,再跳 $pre$。当 $x,y$ 都经过同一个点时,就可以确定这个点是 LCA 了。
注意,每跳一步前,都要让当前点移到并查集指向的根,不然会多次经过已经被缩点缩掉的边,导致复杂度不正确。
在一般情况下,时间复杂度趋近 $O(NM +N^2\log N)$,而且和增广路算法一样跑不满。(具体一些细节导致我不会分析复杂度但反正跑的还是很快的 qwq)
一些具体实现比较麻烦,可以通过代码理解。
code
```cpp
#include<bits/stdc++.h>
using namespace std;
int tot,tag[1001],vis[1001],ma[1001],pre[1001],f[1001],n,m,ans;
vector<int> v[1001]; queue<int> q;
inline int find(int x){while (x!=f[x]) x=f[x]=f[f[x]]; return x;}
inline int lca(int x,int y){
++tot;
while (1){
if (x){
x=find(x); if (tag[x]==tot) return x;
tag[x]=tot; x=pre[ma[x]];
}
swap(x,y);
}
}
inline void flower(int x,int y,int p){
while (find(x)!=p){
pre[x]=y; y=ma[x]; vis[y]=1; q.push(y);
if (find(x)==x) f[x]=p;
if (find(y)==y) f[y]=p;
x=pre[y];
}
}
inline void bfs(int st){
for (int i=1;i<=n;++i) pre[i]=vis[i]=0,f[i]=i;
while (!q.empty()) q.pop();
vis[st]=1; q.push(st);
while (!q.empty()){
int x=q.front(); q.pop();
for (int y:v[x]) if (find(y)!=find(x) && vis[y]!=2){
if (vis[y]==1){
int l=lca(x,y); flower(x,y,l); flower(y,x,l); continue;
}
vis[y]=2; pre[y]=x;
if (!ma[y]){
int px=y;
while (px){
int py=pre[px],pz=ma[py];
ma[px]=py; ma[py]=px; px=pz;
}
++ans; return;
}
vis[ma[y]]=1; q.push(ma[y]);
}
}
}
int main(){
ios::sync_with_stdio(false); cin.tie(0);
cin>>n>>m;
for (int i=1;i<=m;++i){
int x,y; cin>>x>>y;
v[x].push_back(y),v[y].push_back(x);
}
for (int i=1;i<=n;++i) if (!ma[i]) bfs(i);
cout<<ans<<'\n'; for (int i=1;i<=n;++i) cout<<ma[i]<<' ';
return 0;
}
```