CF178F3 Representative Sampling
题目描述
ABBYY 的聪明海狸与“细胞学与遗传学研究所”有着长期的合作历史。最近,研究所的工作人员给海狸出了一个新问题。问题如下。
有一个包含 $n$ 个蛋白质(不一定各不相同)的集合。每个蛋白质是由小写拉丁字母组成的字符串。科学家们要求海狸从初始的蛋白质集合中选出一个大小为 $k$ 的子集,使得所选蛋白质子集的代表性最大。
ABBYY 的聪明海狸经过研究后得出,蛋白质集合的代表性可以用一个简单的数值来衡量。假设我们有一个包含 $k$ 个字符串 $ \{a_{1},...,a_{k}\} $ 的蛋白质集合,其代表性定义如下:
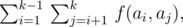
其中 $f(x,y)$ 表示字符串 $x$ 和 $y$ 的最长公共前缀的长度。例如,$f($"abc", "abd"$)=2$,$f($"ab", "bcd"$)=0$。
因此,蛋白质集合 $\{$"abc", "abd", "abe"$\}$ 的代表性为 $6$,而集合 $\{$"aaa", "ba", "ba"$\}$ 的代表性为 $2$。
了解了这一点后,ABBYY 的聪明海狸要求杯赛选手编写一个程序,从给定的蛋白质集合中选出一个大小为 $k$ 的子集,使其代表性最大。请你帮助他解决这个问题!
输入格式
第一行包含两个整数 $n$ 和 $k$($1 \leq k \leq n$),用一个空格隔开。接下来的 $n$ 行,每行一个蛋白质的描述。每个蛋白质是一个非空字符串,仅由小写拉丁字母(a...z)组成,长度不超过 $500$。有些字符串可能相同。
获得 20 分的输入范围:
- $1 \leq n \leq 20$
获得 50 分的输入范围:
- $1 \leq n \leq 100$
获得 100 分的输入范围:
- $1 \leq n \leq 2000$
输出格式
输出一个整数,表示从给定蛋白质集合中选出大小为 $k$ 的子集所能获得的最大代表性。
说明/提示
由 ChatGPT 4.1 翻译