CF520C DNA Alignment
题目描述
Vasya 对生物信息学产生了兴趣。他打算写一篇关于相似环状 DNA 序列的文章,因此他发明了一种判断环状序列相似性的新方法。
假设字符串 $s$ 和 $t$ 的长度均为 $n$,那么函数 $h(s,t)$ 定义为 $s$ 和 $t$ 相应位置上相同符号的个数。函数 $h(s,t)$ 可用于定义 Vasya 距离函数 $ρ(s,t)$:
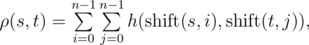
其中  表示对字符串 $s$ 左循环移动 $i$ 次所得到的字符串。例如,
$$
ρ(\text{"AGC"},\text{"CGT"}) = h(\text{"AGC"},\text{"CGT"})+h(\text{"AGC"},\text{"GTC"})+h(\text{"AGC"},\text{"TCG"})+ h(\text{"GCA"},\text{"CGT"})+h(\text{"GCA"},\text{"GTC"})+h(\text{"GCA"},\text{"TCG"})+ h(\text{"CAG"},\text{"CGT"})+h(\text{"CAG"},\text{"GTC"})+h(\text{"CAG"},\text{"TCG"}) = 1+1+0+0+1+1+1+0+1=6
$$
Vasya 在网上找到了一个长度为 $n$ 的字符串 $s$。现在他想统计有多少个字符串 $t$,使得字符串 $s$ 到 $t$ 的 Vasya 距离达到最大可能值。换句话说,$t$ 必须满足:

Vasya 无法枚举所有可能的字符串用于查找答案,因此他需要你的帮助。由于答案可能非常大,请你输出答案对 $10^{9}+7$ 取模后的结果。
输入格式
第一行输入一个整数 $n$,表示字符串的长度,满足 $1 \leq n \leq 10^5$。
第二行输入一个长度为 $n$ 的字符串,只包含字符 "A"、"C"、"G"、"T"。
输出格式
输出一个整数,表示满足条件的字符串个数,对 $10^{9}+7$ 取模。
说明/提示
请注意,如果对于两个不同的字符串 $t_1$ 和 $t_2$,它们的 $ρ(s,t_1)$ 和 $ρ(s,t_2)$ 在所有可能的 $t$ 中达到最大值,则它们都需要计入答案,即使两者相互之间可以通过循环位移得到。
在第一个样例中,有 $ρ(\text{"C"},\text{"C"})=1$,其他长度为 1 的字符串 $t$ 对应的 $ρ(s,t)$ 都为 0。
在第二个样例中,有 $ρ(\text{"AG"},\text{"AG"})=ρ(\text{"AG"},\text{"GA"})=ρ(\text{"AG"},\text{"AA"})=ρ(\text{"AG"},\text{"GG"})=4$。
在第三个样例中,有 $ρ(\text{"TTT"},\text{"TTT"})=27$。
由 ChatGPT 5 翻译