P17020 [ROI 2026 Day1] 括号和树【暂未配置评测】
题目背景
这是一道通信题。
题目描述
本题讨论**无顺序孩子的有根树**。一棵无顺序孩子的有根树由根以及零个或多个孩子构成,每个孩子本身又是一棵无顺序孩子的有根树。同时,正如名称所示,列举孩子时的顺序无关紧要,也就是说,下图中展示的两棵树被视为同一棵无顺序孩子的有根树。后文中,我们将无顺序孩子的有根树简称为**树**。
:::align{center}
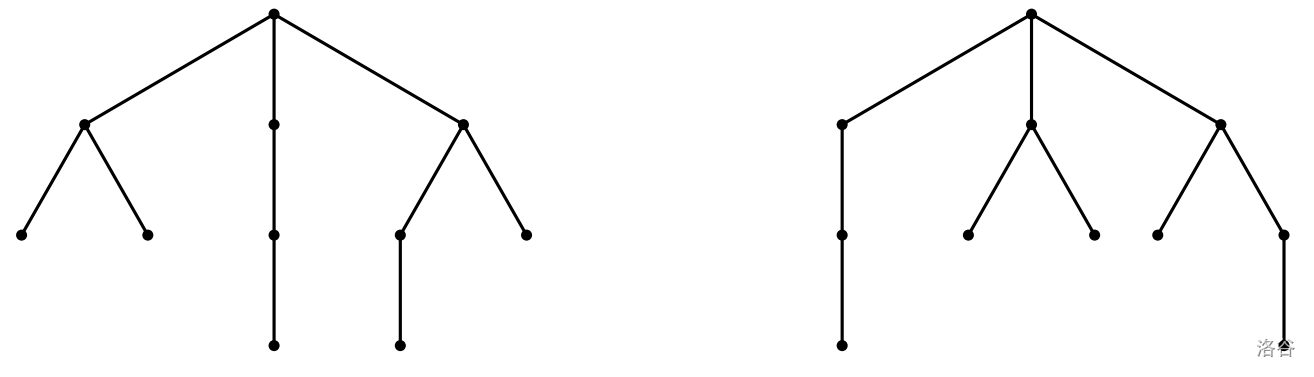
:::
任意一棵树都可以通过如下方式编码为一个**正确括号序列**(以下简称括号序列):
- 仅由一个顶点构成的树编码为 `()`。
- 设去掉根之后,树分解为子树 $t_1, t_2, \ldots, t_k$,其中 $k$ 为原树根的孩子数目。令 $s_1, \ldots, s_k$ 分别为编码 $t_1, \ldots, t_k$ 的字符串。则对 $1$ 到 $k$ 的任意排列 $a = [a_1, a_2, \ldots, a_k]$,原树可以编码为括号序列 `(` $s_{a_1} s_{a_2} \ldots s_{a_k}$ `)`。
注意,同一棵树可能由不同的括号序列编码。例如,下图中所示的树既可以编码为 `(()(()))`,也可以编码为 `((())())`。
:::align{center}
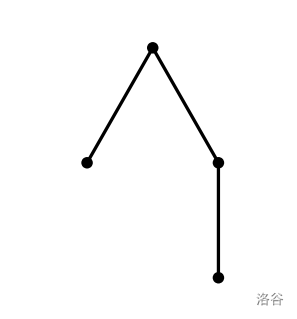
:::
你需要学会将任意一个树序列 $u_1, \ldots, u_n$ 编码为一棵有根树 $w$。为检验你的编码方式是否正确,你的程序将被运行两次。
**第一次运行**
在第一次运行时,程序会收到 $n$ 个正确括号序列,每个序列都是某棵有根树的编码 $s_i$。作为应答,你需要输出一个正确括号序列,表示某棵有根树 $w$。不同子任务对树 $w$ 的顶点数(取决于原始树的总顶点数)有不同限制。
**第二次运行**
在第二次运行时,程序会收到一个单独的正确括号序列,它编码了第一次运行时你输出的树 $w$。需要注意的是,输入可以是树 $w$ 的任意一个合法编码,不一定是你的程序第一次运行时输出的那个序列。
作为应答,你需要输出若干个正确括号序列,它们应当与第一次运行时输入的那些树一一对应,且顺序相同。对于每棵树,你可以输出它的任意一种编码括号序列,但整列中的顺序必须与第一次运行时输入的顺序一致。
### 交互协议
每次运行开始时,你的程序应读入一个整数 $t$($t = 1$ 或 $2$),表示当前是第几次运行。
**第一次运行**
你需要处理多组输入数据。每组数据通过标准输入流交互给出:也就是说,在读入下一组数据之前,你必须先输出当前组的答案并刷新标准输出流缓冲区。
每组数据的第一行包含一个整数 $n$,表示需要编码的树的数量。若 $n = 0$,说明所有数据已处理完毕,程序应终止。否则,接下来的 $n$ 行每行给出一个由 `(` 和 `)` 组成的字符串 $s_i$,即按题述方式编码第 $i$ 棵树的正确括号序列。保证 $s_i$ 描述了一棵合法的树。
对于该组数据,你的程序应输出一个正确括号序列,编码某棵树 $w$。输出后,须换行并刷新输出流缓冲区。
本题在第一次运行时,评测程序是**自适应**的。这意味着评测程序在生成当前测试点的后续数据组时,可能会利用你在之前各组中输出的树 $w$。
**第二次运行**
你需要处理多组输入数据。每组数据包含一个字符串 $s$。若 $s$ 为 `0`,则表示所有数据已处理完毕,程序应终止。否则 $s$ 是一个正确括号序列,编码了第一次运行时你生成的某棵树 $w$。
对于每组数据,你需要输出两行:第一行包含一个整数 $n$,即解码出的树的数量。第二行由 $n$ 个正确括号序列组成,它们按对应顺序编码了第一次运行时输入的那些树,序列之间用 `+` 分隔。例如,如果需要依次输出 `(())` 和 `(()())`,则应输出:
```
2
(())+(()())
```
每次输出后须换行并刷新输出流缓冲区。
注意,每次输出后请勿忘记换行,并正确刷新输出流。请参阅选手须知了解在交互题中如何刷新输出流。
输入格式
无
输出格式
无
说明/提示
### 子任务
记单组输入数据中所有括号序列的总长度为 $s$,并记你的程序在第一次运行时对该组数据输出的长度为 $m$。每个子任务定义了一个函数 $f(x)$,若对于每组数据均满足 $m \le f(s)$ 且所有树均被正确恢复,则该子任务被视为通过。
记第 $i$ 棵树的顶点数为 $t_i$,则字符串 $s_i$ 的长度为 $2 t_i$。
记 $S$ 为同一测试点中所有数据组的 $s$ 之和。保证每个测试点中 $S \le 10^6$,且数据组数不超过 $100$。
| 子任务 | 分数 | $f(x)$ | $S$ | 额外限制 | 依赖子任务 |
|:---:|:---:|:---:|:---:|:---|:---:|
| 1 | 13 | $f(x) = x + 2000$ | $S \le 200\,000$ | 第二次运行时给出的括号序列与你的程序在第一次运行时输出的序列**完全相同**。 | |
| 2 | 7 | $f(x) = x + 2000$ | $S \le 200\,000$ | $t_1 < t_2 < \ldots < t_n$ | |
| 3 | 6 | $f(x) = x + 2000$ | $S \le 200\,000$ | $n = 2$ | |
| 4 | 最高 34 | $f(x) = 4x + 2000$ | $S \le 200\,000$ | | |
| 5 | 最高 11 | $f(x) = x + 2000$ | | $t_1 = t_2 = \ldots = t_n > 1$ | |
| 6 | 最高 9 | $f(x) = x + 2000$ | | $t_i > 1$ | 5 |
| 7 | 最高 20 | $f(x) = x + 2000$ | | | 1 – 6 |
子任务 4 的计分方式如下。对每组数据定义 $k = \max\left(0, \dfrac{m - 2000}{s}\right)$,函数 $\operatorname{score}(k)$ 由下表给出:
| $k$ | $\operatorname{score}(k)$ |
|:---:|:---:|
| $\le 1.5$ | $34$ |
| $2$ | $20$ |
| $3$ | $10$ |
| $4$ | $5$ |
| $> 4$ | $0$ |
对于 $k$ 的中间取值,函数值在表格相邻两行之间线性插值,并四舍五入到最接近的整数。测试点得分为该测试点所有数据组 $\operatorname{score}(k)$ 的最小值,子任务得分为其各测试点得分的最小值。
子任务 5、6、7 同样按以下方式计分。对每组数据定义 $c = \max(0, m - s)$,函数 $\operatorname{score}(c)$ 由下表给出:
| $c$ | $\operatorname{score}(c)$,子任务 5 | $\operatorname{score}(c)$,子任务 6 | $\operatorname{score}(c)$,子任务 7 |
|:---:|:---:|:---:|:---:|
| $\le 30$ | $11$ | $9$ | $20$ |
| $100$ | $7$ | $7$ | $14$ |
| $200$ | $4$ | $4$ | $8$ |
| $2000$ | $2$ | $2$ | $4$ |
| $> 2000$ | $0$ | $0$ | $0$ |
对于 $c$ 的中间取值,函数值同样在相邻行之间线性插值并四舍五入。测试点得分为该测试点所有数据组 $\operatorname{score}(c)$ 的最小值,子任务得分为其各测试点得分的最小值。
翻译由 DeepSeek V4 Pro 完成