SP1789 GREEDULM - Huffman´s Greed
题目描述
以下是关于树的一些基本术语。我们可以递归地定义一棵**树**:它有一个**根节点**,这个节点要么是一个**外部节点**(叶子),要么是一个拥有多个子树的**内部节点**。一个内部节点也被称为其子树根节点的**父节点**。通过递归定义,树中节点的**层级**是:根节点的层级为 `0`,而某个节点的层级则比其父节点多 `1`。
在**二叉树**中,每个内部节点都有两个子节点,分别是左子树和右子树。如果每个内部节点都标记了一个字符串(标签),那么这个树就是**带标签的二叉树**。若满足如下条件:每个节点 `t` 的左子树中的节点标签都小于 `t` 的标签,并且 `t` 的标签小于右子树中所有节点的标签,这样的树即为**二叉搜索树**。这里假设字符串按照字典序排列。
树的**中序遍历**是这样定义的:对于叶子节点,直接访问;对于内部节点,首先中序遍历其左子树,然后访问节点本身,最后中序遍历其右子树。因此,二叉搜索树的中序遍历会按字典序排列节点标签。需要注意的是,即使是形状不同的二叉搜索树,中序遍历的结果序列也可能相同。
如果我们在二叉搜索树中查找一个字符串 `s`,首先将 `s` 与根节点的标签 `l` 进行比较。如果 `s=l`,查找完成;如果 `sl`,继续在右子树查找。如果查找到叶子节点,则说明 `s` 不在树中。
查找过程中比较的次数取决于 `s` 和搜索树的布局。因此,人们希望构建一种二叉搜索树,既能存储给定的字符串序列,又能尽量减少查找步骤。当然,我们无法提前知道哪些字符串会被查找,所以我们需要一些假设。
设 `n` 为要存储的字符串数。把这些字符串按字典序排列为 `K_{1}, K_{2}, ..., K_{n}`。同时,有一组非负数 `p_{1}, p_{2}, ..., p_{n}` 和 `q_{0}, q_{1}, ..., q_{n}` 满足 `∑_{i=1..n} p_{i} + ∑_{i=0..n} q_{i} = 1`。它们的含义是:
- `p_{i}` 表示查找参数 `s` 是 `K_{i}` 的概率。
- `q_{i}` 表示 `s` 位于 `K_{i}` 和 `K_{i+1}` 之间的概率。
根据惯例,`q_{0}` 是 `s` 小于 `K_{1}` 的概率,`q_{n}` 是 `s` 大于 `K_{n}` 的概率。我们的目标是找出一个二叉搜索树,使得包含标签 `K_{1}, ..., K_{n}` 的节点,这样可以最小化搜索的期望比较次数,即:
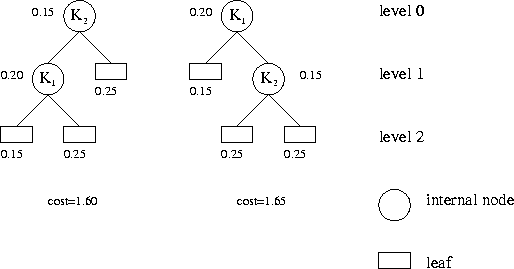
`cost = ∑_{i=1..n} p_{i} * (1 + K_{i} 的节点层级) + ∑_{i=0..n} q_{i} * (在 K_{i} 和 K_{i+1} 之间查找时到达的叶子节点的层级)`。在查找位于 `K_{i}` 和 `K_{i+1}` 之间的字符串 `s` 时到达的叶子节点,我们需要遵循这个处理方式。
下图展示了一个样例的测试用例,展示了两种可能的二叉搜索树、各自的概率以及访问代价。
**本翻译由 AI 自动生成**
输入格式
无
输出格式
无