SP410 VHUFFM - Variable Radix Huffman Encoding
题目描述
霍夫曼编码是一种利用目标字母表为源字母表中的符号进行最优编码的方法,前提是源字母表中每个符号的频率已知。所谓最优编码,就是指编码后的消息平均长度最短。在本题中,你需要为前 $N$ 个大写字母(源字母表,从 $A$ 开始,频率分别为 $f_1$ 到 $f_N$)到前 $R$ 个十进制数字(目标字母表,从 $0$ 到 $R-1$)进行编码。
对于 $R=2$ 的情况,编码过程涉及多个步骤。在每一步中,选择频率最低的两个源符号(例如 $A$ 和 $B$),并将它们组合成一个新的“组合字母”,其频率是 $f_A$ 和 $f_B$ 的和。如果出现频率相同的情况,则选择字母表中位置靠前的字母。经过多次组合,只余下两个字母。在这些步骤中,每一对组合的字母都会被分配一个来自目标字母表的符号。
频率较低的字母被分配代码 $0$,频率较高的字母分配代码 $1$。(如果组合中的字母频率相同,则字母表中靠前的分配代码 $0$。在比较时,“组合字母”的值是该组合中最早字母的值。)最终的编码序列是通过将每次组合时分配的目标字母表符号进行连接而形成的。
目标字母表的符号要按照它们被分配的逆序进行连接,因此最终编码序列的第一个符号是最后分配的符号。
下图展示了 $R=2$ 时的编码过程。
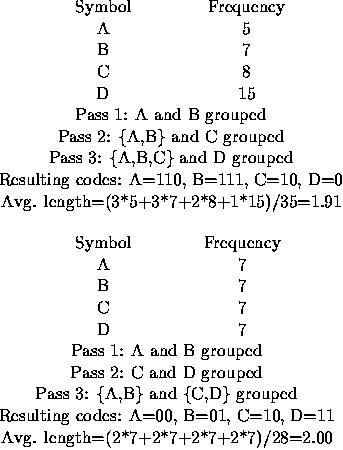
当 $R > 2$ 时,每一步要组合 $R$ 个字母。因为这样做相当于在每一步用一个组合字母替换掉 $R$ 个字母,并且最后必须组合 $R$ 个字母,所以源字母表中必须包含 $k \cdot (R-1) + R$ 个字母,其中 $k$ 是一个整数。
由于 $N$ 可能不足,因此需要引入虚拟字母,这些字母的频率为零,并不会出现在输出中。在比较时,虚拟字母排列在字母表中的最后。
确定霍夫曼编码的基本过程与 $R=2$ 时相同。在每一步,选出频率最低的 $R$ 个字母进行组合,形成一个新的组合字母,其频率为所组合字母频率之和。而这些组合中字母的排序则根据目标字母表的符号 $0$ 到 $R-1$ 进行。频率最低的字母编号为 $0$,依次类推。同频率的字母中,字母表顺序靠前的被分配较小的目标编号。
下图展示了 $R=3$ 时的编码过程。

输入格式
输入包含一个或多个数据集,每行一个。每个数据集由一个整数 $R$(范围为 2 到 10)、一个整数 $N$(范围为 2 到 26),以及 $N$ 个源字母表频率 $f_1$ 到 $f_N$(每个频率范围为 1 到 999)构成。
数据结束标志为 $R$ 为 0,这个标志不属于数据集。
输出格式
对于每个数据集,输出其编号(编号从 1 开始)和平均目标符号长度,保留两位小数。接着输出源字母表中的 $N$ 个字母及其对应的霍夫曼编码,每行一个字母及其编码。
每个测试用例输出后请另起一行空行。
提示示例会说明所需的输出格式。
**本翻译由 AI 自动生成**