SP410 VHUFFM - Variable Radix Huffman Encoding
Description
Huffman encoding is a method of developing an optimal encoding of the symbols in a _source alphabet_ using symbols from a _target alphabet_ when the frequencies of each of the symbols in the source alphabet are known. Optimal means the average length of an encoded message will be minimized. In this problem you are to determine an encoding of the first _N_ uppercase letters (the source alphabet, 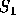 through 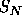 , with frequencies 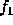 through 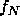 ) into the first _R_ decimal digits (the target alphabet, 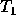 through 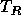 ).
Consider determining the encoding when _R_=2. Encoding proceeds in several passes. In each pass the two source symbols with the lowest frequencies, say 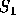 and 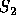 , are grouped to form a new ``combination letter" whose frequency is the sum of 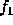 and 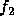 . If there is a tie for the lowest or second lowest frequency, the letter occurring earlier in the alphabet is selected. After some number of passes only two letters remain to be combined. The letters combined in each pass are assigned one of the symbols from the target alphabet.
The letter with the lower frequency is assigned the code 0, and the other letter is assigned the code 1. (If each letter in a combined group has the same frequency, then 0 is assigned to the one earliest in the alphabet. For the purpose of comparisons, the value of a ``combination letter" is the value of the earliest letter in the combination.) The final code sequence for a source symbol is formed by concatenating the target alphabet symbols assigned as each combination letter using the source symbol is formed.
The target symbols are concatenated in the reverse order that they are assigned so that the first symbol in the final code sequence is the last target symbol assigned to a combination letter.
The two illustrations below demonstrate the process for _R_=2.
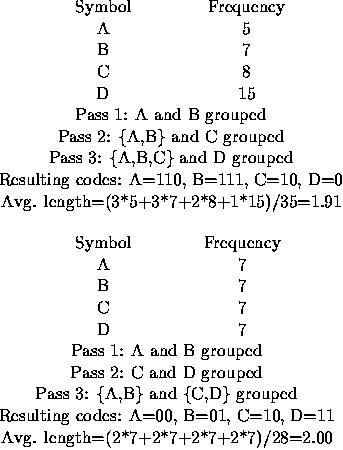
When _R_ is larger than 2, _R_ symbols are grouped in each pass. Since each pass effectively replaces _R_ letters or combination letters by 1 combination letter, and the last pass must combine _R_ letters or combination letters, the source alphabet must contain _k_\*(_R_-1)+_R_ letters, for some integer _k_.
Since _N_ may not be this large, an appropriate number of fictitious letters with zero frequencies must be included. These fictitious letters are not to be included in the output. In making comparisons, the fictitious letters are later than any of the letters in the alphabet.
Now the basic process of determining the Huffman encoding is the same as for the _R_=2 case. In each pass, the _R_ letters with the lowest frequencies are grouped, forming a new combination letter with a frequency equal to the sum of the letters included in the group. The letters that were grouped are assigned the target alphabet symbols 0 through _R_-1. 0 is assigned to the letter in the combination with the lowest frequency, 1 to the next lowest frequency, and so forth. If several of the letters in the group have the same frequency, the one earliest in the alphabet is assigned the smaller target symbol, and so forth.
The illustration below demonstrates the process for _R_=3.

Input Format
The input will contain one or more data sets, one per line. Each data set consists of an integer value for _R_ (between 2 and 10), an integer value for _N_ (between 2 and 26), and the integer frequencies 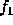 through 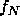 , each of which is between 1 and 999.
The end of data for the entire input is the number 0 for _R_; it is not considered to be a separate data set.
Output Format
For each data set, display its number (numbering is sequential starting with 1) and the average target symbol length (rounded to two decimal places) on one line. Then display the _N_ letters of the source alphabet and the corresponding Huffman codes, one letter and code per line.
Print a blank line after each test case.
The examples below illustrate the required output format.